Основные типы моделей данных. с помощью экранных форм, специально созданных для этого пользователем
Ядром любой базы данных является модель данных. Модель данных - совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или не некотором их подмножестве.
Иерархическая модель данных.
К основным понятиям иерархической структуры относятся: уровень, элемент, связь. Узел это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне (см. рис. 5).
Рис. 5. Иерархическая модель данных
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, для записи С4 путь проходит через записи А и В3.
Пример иерархической структуры. Каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) факультету (см. рис. 6).

Рис. 6. Пример иерархической организации данных
Сетевая модель данных
В сетевой структуре каждый элемент может быть связан с любым другим элементом (см. рис 7).

Рис. 7. Сетевая модель данных
Пример сетевой структуры. База данных, содержащая сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС (см. рис. 8).

Рис. 8. Пример сетевой организации данных
Реляционная модель данных
Эти модели характеризуются простотой структуры данных, удобным для пользователя представлением и возможностью использования формального аппарата алгебры отношений.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица (отношение) представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы - один элемент данных;
· все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
· каждый столбец имеет уникальное имя;
· одинаковые строки в таблице отсутствуют;
· порядок следования строк и столбцов может быть произвольным.
Пример. Реляционной таблицей можно представить информацию о студентах, обучающихся в вузе.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
Одни и те же данные могут группироваться в таблицы различными способами. Группировка атрибутов в таблицах должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки.
Нормализация отношений - формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Выделяют пять нормальных форм отношений. Эти формы предназначены для уменьшения избыточности информации от первой до пятой нормальных форм. Поэтому каждая последующая нормальная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. При практическом проектировании баз данных четвертая и пятая формы, как правило, не используются.
Процедуру нормализации рассмотрим на примере проектирования многотабличной БД Продажи , содержащей следующую информацию:
· Сведения о покупателях.
· Дату заказа и количество заказанного товара.
· Дату выполнения заказа и количество проданного товара.
· Характеристику проданного товара (наименование, стоимость, марка).
Таблица 2. Структура таблицы Продажи
Таблицу Продажи можно рассматривать как однотабличную БД. Основная проблема заключается в том, что в ней содержится значительное количество повторяющейся информации. Такая структура данных является причиной следующих проблем, возникающих при работе с БД:
· Приходится тратить значительное время на ввод повторяющихся данных. Например, для всех заказов, сделанных одним покупателем, придется каждый раз вводить одни и те же данные о покупателе.
· При изменении адреса или телефона покупателя необходимо корректировать все записи, содержащие сведения о заказах этого покупателя.
· Наличие повторяющейся информации приведет к неоправданному увеличению размера БД. В результате снизится скорость выполнения запросов. Кроме того, повторяющиеся данные нерационально используют дисковое пространство компьютера.
· Любые нештатные ситуации потребуют значительного времени для получения требуемой информации.
Известны три типа моделей описания баз данных (рис.3.7):
ü иерархическая;
ü сетевая;
ü реляционная.
Основное различие между ними состоит в характере описания взаимосвязей и взаимодействия между объектами и атрибутами базы данных.
Рис 3.7. Основные типы моделей данных
1. Иерархическую модель БД изображают в виде дерева. Каждой вершине соответствует множество экземпляров записей, составляющих логический файл. Вершины расположены по уровням и связаны между собой отношениями подчиненностями. Одна-единственная вершина верхнего уровня является корневой (рис.3.8).
Достоинством модели является:
· простота ее построения;
· легкость понимания сути принципа иерархии;
· наличие промышленных СУБД, поддерживающих данную модель.
Недостатком является сложность операций по включению в иерархию информации о новых объектах базы данных и удалению устаревшей информации.

Рис. 3.8. Иерархическая модель данных
2. Сетевая модель описывает элементарные данные и отношения между ними в виде ориентированной сети. Это такие отношения между объектами, когда каждый порожденный элемент имеет более одного исходного и может быть связан с любым другим элементом структуры рис.3.9).
Сетевые структуры могут быть многоуровневыми, иметь разную степень сложности.
База данных, описываемая сетевой моделью, состоит из областей (области - из записей, а записи - из полей).
Недостатком сетевой модели является ее сложность, возможность потери независимости данных при реорганизации базы данных. При появлении новых пользователей, новых приложений и новых видов запросов происходит рост базы данных, что может привести к нарушению логического представления данных.

Рис.3.9. Сетевая модель данных
3. Реляционная модель БД представляет объекты и взаимосвязи между ними в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. На этой модели базируются практически все современные СУБД.
Реляционная модель имеет в своей основе понятие «отношения», и ее данные формируются в виде таблиц. Отношение - это двумерная таблица, имеющая свое название, в которой минимальным объектом действий, сохраняющим ее структуру, является строка таблицы (кортеж), состоящая из ячеек таблицы - полей.
Каждый столбец таблицы соответствует только одному компоненту этого отношения. С логической точки зрения реляционная база данных представляется множеством двумерных таблиц различного предметного наполнения.
В реляционной базе данных СУБД поддерживает извлечение информации из БД на основе логических связей. При работе с БД не надо программировать связи с файлами, что позволяет одной командой обрабатывать все файлы данных и повышать эффективность программирования БД. Благодаря снижению требований к квалификации разработчиков существенно расширяется круг пользователей баз данных, информационные базы данных стали стандартом СУБД для информационных систем.

Рис.3.10 Реляционная модель данных
В зависимости от содержания отношения реляционные базы данных бывают:
ü объектными, в которых хранятся данные о каком-либо одном объекте, экземпляре сущности. В них один из атрибутов однозначно определяет объект и называется ключом отношения, или первичным атрибутом. Остальные атрибуты функционально зависят от этого ключа;
ü связными, в которых хранятся ключи нескольких объектных отношений, по которым между ними устанавливаются связи.
Достоинства реляционной модели:
· простота построения;
· доступность понимания;
· возможность эксплуатации базы данных без знания методов и способов ее построения;
· независимость данных;
· гибкость структуры и др.
Недостатки реляционной модели:
· низкая производительность по сравнению с иерархической и сетевой моделями;
· сложность программного обеспечения;
· избыточность элементов.
В последние годы все большее признание и развитие получают объектно-ориентированные базы данных (ООБД).
Принципиальное отличие реляционных и объектно-ориентированных баз данных заключается в следующем : в ООБД модель данных более близка сущностям реального мира, объекты можно сохранить и использовать непосредственно, не раскладывая их по таблицам, типы данных определяются разработчиком и не ограничены набором предопределенных типов.
Традиционными областями применения объектных СУБД являются системы автоматизированного проектирования (САПР), моделирование, мультимедиа.
К объектным СУБД можно отнести СУБД ONTOS - одного из лидеров направляя ООБД, Jasmine. ODB-Jupiter - первый российский продукт такого рода, ORACLE 8.0.
Базы знаний - это специальные компьютерные системы, основанные на обобщении, анализе и оценке знаний высококвалифицированных специалистов-экспертов.
Например, «КонсультантПлюс», «Гарант Сервис».
Основными элементами информационной технологии, используемой в БЗ являются:
Интерпретатор,
Модуль создания системы,
Интерфейс используется для ввода запросов и команд в экспертную систему и получает выходную информацию из нее.
Выходная информация включает не только само решение, но необходимые объяснения, которые могут быть двух видов:
1) по запросам, т.е. те, которые пользователь может получить в любой момент;
2) которые пользователь получает уже при выдаче решения, т.е. то, каким образом получается решение (например, каким образом влияет на прибыль и издержки выбранная цена и т.д.).
К базе знаний относятся факты, характеризующие проблемную область, а также их логическая взаимосвязь. Центральным звеном здесь являются правила, которые даже в простейшей задаче экспертных систем могут насчитывать тысячи. Правила определяют порядок действий в конкретной ситуации при выполнении того или другого условия.
Интерпретатор в определенном порядке проводит обработку знаний, находящихся в базе. Используются также и дополнительные блоки: база данных, блоки расчета, ввода, корректировки данных.
Модуль создания системы служит для создания набора правил, внесения в них изменений. Здесь могут использоваться как специальные алгоритмические языки (ЛИСП, Пролог), так и оболочки экспертных систем.
Более совершенным считается использование оболочек экспертных систем, т.е. программных средств, ориентированных на решение определенной проблемы путем создания соответствующей ей базы знаний. Этот путь, как правило, более быстрый и менее трудоемкий.
1. В чем различие между информацией и данными?
2. Как выражается адекватность информации?
3. Назовите признаки классификации экономической информации.
4. Что такое структура информации?
5. Чем показатель отличается от реквизита?
6. Укажите основные свойства информации.
7. Что входит в состав информационного обеспечения?
8. Чем внемашинное информационное обеспечение отличается от внуримашинного?
9. Какие бывают классификаторы и с какой целью разрабатываются классификаторы?
10. Каково назначение штрихового кодирования? В чем его особенности?
11. Определите понятия «классификаторы» и «коды».
12. Чем автоматизированные банки данных отличаются от баз знаний?
13. Что входит в состав автоматизированных банков данных?
14. Чем клиент-серверная архитектура отличается от файл-серверной?
15. Укажите основные характеристики СУБД.
16. Что подразумевает обеспечение целостности данных?
17. Охарактеризуйте типы моделей описания баз данных.
4. информационные технологии в управлении и экономике
Лекция 5
Базы данных информационных систем
База данных. Классификация и характеристика СУБД.
Основные модели баз данных.
Базы данных в экономических системах
База данных определяется как совокупность взаимосвязанных данных, характеризующихся: возможностью использования для большого количества приложений; возможностью быстрого получения и модификации необходимой информации; минимальной избыточностью информации; независимостью от прикладных программ; общим управляемым способом поиска.
СУБД – это программа, с помощью которой реализуется централизованное управление данными, хранимыми в базе, а также доступ к ним, поддержка их в актуальном режиме.
Задачами СУБД являются:
Хранение информации в структурированном виде;
Обновление информации по мере необходимости;
Поиск нужной информации по определенным критериям;
Выдача информации пользователю в удобном для него виде;
Устранение избыточности данных;
Поддержка языков БД.
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных.
По технологии работы с базами данных существуют:
Централизованные СУБД;
Распределенные СУБД.
Централизованная СУБД - система управления базой данных, которая хранится в памяти одной вычислительной системы.
Системы централизованных баз данных с сетевым доступа предполагают две основные архитектуры:
¾ архитектура файл-сервер предполагает выделение одной из машин сети в качестве центральной (главный сервер файлов), где хранится совместно используемая централизованная база данных. Все другие машины сети исполняют роль рабочих станций. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится их обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает;
¾ архитектура клиент-сервер . Каждый из подключенных к сети и составляющих эту архитектуру компьютеров играет свою роль: сервер владеет и распоряжается информационными ресурсами системы, клиент имеет возможность пользоваться ими.
Сервер базы данных представляет собой СУБД, параллельно обрабатывающую запросы, поступившие со всех рабочих станций. Как правило, клиент и сервер территориально отдалены друг от друга, и в этом случае они образуют систему распределенной обработки данных.
В распределенной СУБД значительная часть программно-аппаратных средств централизована и находится на одном достаточно мощном компьютере (сервере), в то время как компьютеры пользователей несут относительно небольшую часть СУБД, которую называют клиентом.
Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Однако пользователь распределенной базы данных не обязан знать, каким образом ее компоненты размещены в узлах сети, и представляет себе эту базу данных как единое целое. Работа с такой базой данных осуществляется с помощью системы управления распределенной базой данных (СУРБД).
Безопасность данных в базе данных достигается:
¾ шифрованием прикладных программ;
¾ шифрованием данных;
¾ защитой данных паролем;
¾ ограничением доступа к базе данных.
Основные модели баз данных
Основное различие между моделями баз данных состоит в характере описания взаимосвязи и взаимодействия между объектами и атрибутами базы данных. Связи объектов могут быть следующих типов:
¾ "один к одному";
¾ "один ко многим";
¾ "многие ко многим".
"Один к одному" - это взаимно однозначное соответствие, которое устанавливается между одним объектом и одним атрибутом. Связь "один-к-одному" определяет такое отношение между таблицами, когда каждой записи в подчиненной таблице соответствует только одна запись в главной таблице. Наличие связей между таблицами "один-к-одному" обычно не говорит о хорошей структуре базе данных, поскольку свидетельствует о том, что две таблицы имеют полностью совпадающие поля, а это ведет к нерациональному расходу дискового пространства.
Связь "один-ко-многим" в структурах баз данных является наиболее общепринятой. При этом типе связи каждой записи главной таблицы соответствует одна или несколько записей в подчиненной таблице. Структура связей типа "один-ко-многим" позволяет избежать избыточности данных и дублирования записей.
Связь типа "многие-ко-многим" выражает такое отношение между таблицами, когда многие записи одной таблицы могут быть связаны со многими записями другой таблицы.
Иерархическая модель баз данных (ИМД) основана на графическом способе и предусматривает поиск данных по одной из ветвей «дерева», в котором каждая вершина имеет только одну связь с вершиной более высокого уровня. Для осуществления поиска необходимо указать полный путь к данным, начиная с корневого элемента.
Рис. 1 – Иерархическая модель баз данных
Сетевая модель баз данных (СМД) также основана на графическом способе, но допускает усложнение «дерева» без ограничения количества связей, входящих в вершину. Это позволяет строить сложные поисковые структуры.

Рис. 2 – Сетевая модель баз данных
Реляционная модель баз данных (РМД) реализует табличный способ.
В реляционной модели базы данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями .
Отношения обладают следующими свойствами :
¾ каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют);
¾ элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена;
¾ в таблице нет двух одинаковых строк;
¾ строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
Реляционная модель БД имеет дело с тремя аспектами данных: со структурой данных, с целостностью данных и с манипулированием данными. Под структурой понимается логическая организация данных в БД, под целостностью данных понимают безошибочность и точность информации, хранящейся в БД, под манипулированием данными - действия, совершаемые над данными в БД.
Достоинства реляционной модели :
¾ простота построения;
¾ доступность понимания;
¾ возможность эксплуатации базы данных без знания методов и способов ее построения;
¾ независимость данных;
¾ гибкость структуры и др.
Недостатки реляционной модели :
¾ низкая производительность по сравнению с иерархической и сетевой модели;
¾ сложность программного обеспечения;
¾ избыточность элементов.
В последние годы все большее признание и развитие получают объектные базы данных (ОБД), появление которых обусловлено развитием объектно-ориентированного программирования.
Объектом называют почти все, что представляет интерес для решения поставленной задачи на компьютере. Это может быть экранное окно, кнопка в окне поле для ввода данных, пользователь программы, сама программа и т.д. Тогда любые действия можно привязать к такому объекту, а также описать, что произойдет с объектом при выполнении опреде6ленных действий (например, при „нажатии“ кнопки). Многократно используемый объект можно сохранить и применять его в различных программах.
Объектом называется программно связанный набор методов (функций) и свойств, выполняющих одну функциональную задачу.
Свойство - это характеристика, с помощью которой описывается внешний вид и работа объекта.
Событие - это действие, которое связанно с объектом. Событие может быть вызвано пользователем (щелчок мышью), инициировано прикладной программой или операционной системой.
Метод - это функция или процедура, управляющая работой объекта при его реакции на событие.
Объекты могут быть как визуальными, т.е. которые можно увидеть на экране дисплея (окно, пиктограмма, текст и т.д.), так и невизуальные (например, программа решения какой-либо функциональной задачи).
Иерархические базы данных имеют форму деревьев с дугами-связями и узлами-элементами данных. Иерархическая структура предполагала неравноправие между данными - одни жестко подчинены другим. Подобные структуры, безусловно, четко удовлетворяют требованиям многих, но далеко не всех реальных задач.2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Во-первых , все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель - единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково - таблицами . Правда, такой подход усложняет понимание смысла хранящейся в базе данных информации, и, как следствие, манипулирование этой информацией.
Избежать трудностей манипулирования позволяет второй элемент модели - реляционно-полный язык (отметим, что язык является неотъемлемой частью любой модели данных, без него модель не существует). Полнота языка в приложении к реляционной модели означает, что он должен выполнять любую операцию реляционной алгебры или реляционного исчисления ( полнота последних доказана математически Э.Ф. Коддом). Более того, язык должен описывать любой запрос в виде операций с таблицами, а не с их строками. Одним из таких языков является SQL .
Третий элемент реляционной модели требует от реляционной модели поддержания некоторых ограничений целостности . Одно из таких ограничений утверждает, что каждая строка в таблице должна иметь некий уникальный идентификатор , называемый первичным ключом. Второе ограничение накладывается на целостность ссылок между таблицами. Оно утверждает, что атрибуты таблицы, ссылающиеся на первичные ключи других таблиц, должны иметь одно из значений этих первичных ключей.
4. Объектно-ориентированная модель. Новые области использования вычислительной техники, такие как научные исследования, автоматизированное проектирование и автоматизация учреждений, потребовали от баз данных способности хранить и обрабатывать новые объекты - текст, аудио- и видеоинформацию, а также документы. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что такого развитого математического аппарата, на который могла бы опираться общая , не существует. В большой степени, поэтому до сих пор нет базовой объектно-ориентированной модели. С другой стороны, некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. Несмотря на преимущества объектно-ориентированных систем - реализация сложных типов данных , связь с языками программирования и т.п. - на ближайшее время превосходство реляционных СУБД гарантировано.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных
Иерархические базы данных - самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений "предок- потомок ". Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных - невозможность реализовать отношения " многие-ко-многим ", а также ситуации, когда запись имеет несколько предков.
Иерархические базы данных . Иерархические базы данных графически могут быть представлены как перевернутое дерево , состоящее из объектов различных уровней. Верхний уровень ( корень дерева ) занимает один объект , второй - объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка ( объект , более близкий к корню) к потомку ( объект более низкого уровня), при этом объект -предок может не иметь потомков или иметь их несколько, тогда как объект - потомок обязательно имеет только одного предка. Объекты, имеющие общего предка, называются близнецами.
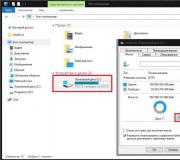
Иерархической базой данных является Каталог папок Windows , с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол . На втором уровне находятся папки Мой компьютер , Мои документы, Сетевое окружение и Корзина , которые являются потомками папки Рабочий стол , а между собой является близнецами. В свою очередь , папка Мой компьютер является предком по отношению к папкам третьего уровня -папкам дисков ( Диск 3,5(А:), (С:), (D:), (Е:), (F:)) и системным папкам ( сканер , bluetooth и.т.д.) - на рис. 4.1 .
Рис.
4.1.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись ( группа ), групповое отношение , база данных .
| Атрибут (элемент данных) | - наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. |
| Запись | - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов. |
| Групповое отношение | - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры. |
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами ( диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись .
Пример
Рассмотрим следующую модель данных предприятия (см. рис. 4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК (НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (
Для логического представления взаимосвязей объектов базы данных используется информационно-логическая (инфологическая) модель.
Известны три разновидности инфологических моделей баз данных:
· иерархическая;
· сетевая;
· реляционная.
Иерархическая модель данных представляет собой древовидную структуру, где каждому элементу (объекту) соответствует только одна связь с элементом (объектом) более высокого уровня. Примером иерархической модели может служить реестр Windows, демонстрирующий размещение файлов и папок разного уровня вложенности на дисках компьютера, а также генеалогическое дерево.
Достоинствами иерархической модели являются простота и быстродействие. Запрос к такой базе обрабатывается быстро, поскольку поиск данных происходит по одной из ветвей дерева, опускаясь от родительских объектов к дочерним или наоборот (поиск вверх по дереву обрабатывается дольше).
Если структура данных предполагает более сложные взаимосвязи, чем обычная иерархия, то для организации информации применяют иные модели.
Сетевая модель данных позволяет, в целях объединения родственной информации, обеспечивать связи одних элементов с любыми другими, не обязательно родительскими. Эта модель подобна иерархической и является улучшенным её вариантом.
В сетевой модели данных каждый элемент может иметь более одного порождающего его элемента, а графическое представление модели напоминает сеть. Она допускает усложнение «дерева» без ограничения количества связей, входящих в его вершину.
Особенностью иерархических и сетевых баз данных является задаваемая заранее, ещё на стадии проектирования, жесткая структура записей и наборы отношений, а изменение структуры базы данных требует перестройки всей базы. Кроме того, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель является зависимой от приложения. Иными словами, если необходимо изменить структуру данных, то может потребоваться и изменение приложения.
Сетевые базы считаются инструментами программистов. Так, например, чтобы получить ответ на запрос: «Какой товар наиболее часто заказывает компания X?», нужно написать некоторый программный код для навигации по базе данных. Реализация пользовательских запросов может затянуться, и к моменту появления запрошенной информации она перестанет быть актуальной.
Реляционная модель достаточно универсальна, она значительно упрощает структуру базы данных и облегчает работу с ней. В реляционной базе данных все данные, доступные пользователю, организованы в виде таблиц. У каждой таблицы имеется свое уникальное имя, соответствующее характеру ее содержимого. Столбцы таблицы, называемые полями , описывают определённые атрибуты информации, например: фамилию, имя, пол, возраст, номер телефона, социальное положение респондентов. Строки реляционной таблицы содержат записи и хранят информацию об одном экземпляре объекта данных, представленного в таблице, например данные об одном человеке. Одинаковых записей в таблице быть не должно.
Основное требование к реляционной базе данных состоит в том, чтобы значения полей (столбцов таблицы) были элементарными и неделимыми информационными единицами (то есть для записи адреса потребуется не одно, а несколько полей, содержащих неделимую информацию – улица, номер дома, номер квартиры). Это позволяет применять для обработки информации математический аппарат реляционной алгебры. Наиболее популярны реляционные СУБД - Access, FoxPro, dBase, Oracle, и др.
В реляционной БД содержится, как правило, несколько таблиц с различными сведениями. Разработчик БД устанавливает связи между отдельными таблицами . При создании связей используют ключевые поля .
После установления связей появляется возможность создания запросов, форм и отчетов, в которые помещаются данные из нескольких связанных между собой таблиц.
Все данные, доступные пользователю в реляционной БД, организованы в виде таблиц-отношений, представляющих собой двумерный массив, где каждая таблица имеет свое уникальное имя, соответствующее характеру ее содержимого.
В настоящее время большинство СУБД использует табличную (реляционную) модель данных.
Достоинства реляционной модели:
· Простота и доступность для понимания конечным пользователем, так как единственной информационной конструкцией является наглядная таблица.
· Полная независимость данных. При изменении структуры БД не требуется значительных изменений в прикладной программе.
Недостатки реляционной модели:
· Предметную область не всегда можно представить в виде совокупности таблиц.
· Низкая скорость обработки запросов по сравнению с другими моделями, а также требование большего объема внешней памяти.
Примером простой реляционной базы данных может служить таблица «Респонденты», где одна строка (запись) - сведения об одном из участников телефонного опроса.