Использование технологии «клиент-сервер. Лекция N2
Следует заметить, что как и любая классификация, наша классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений. Тем не менее, при архитектурном проектировании системы кажется полезным иметь хотя бы частично ортогонализированный архитектурный базис. В следующих частях курса мы подробно рассмотрим особенности каждой архитектуры и остановимся на методологиях и инструментально-технологических средствах, поддерживающих проектирование и разработку информационных систем в соответствующей архитектуре.
2.1. Файл-серверные приложения
По всей видимости, организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Чем привлекает такая организация не очень опытных в области системного программирования разработчиков информационных систем? Скорее всего, тем, что при опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения , работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере. В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных . Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти (рисунок 2.1).
Не останавливаясь подробно на имеющихся на сегодняшнем рынке перспективных инструментальных средствах разработки файл-серверных приложений и не приводя анализа тенденций развития соответствующих технологий (этому посвящается третья часть курса), мы кратко перечислим основные достоинства и недостатки файл-серверных архитектур.
Конечно, основным достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows NT. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Но во многом эта простота является кажущейся. (Как гласит русская пословица, "Простота хуже воровства", а здесь мы, как правило, имеем простоту на основе воровства программных продуктов для PC.)
Рис. 2.1. Классическое представление информационной системы в архитектуре "файл-сервер"
Во-первых, информационной системе предстоит работать с базой данных. Следовательно, эта база данных должна быть спроектирована. Почему-то часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь. Конечно, это неправильно. База данных есть база данных. Чем качественнее она спроектирована, тем больше шансов впоследствии эффективно использовать информационную систему. Естественно, сложность проектирования базы данных определяется объективной сложностью моделируемой предметной области. Но, собственно, из чего должно следовать, что файл-серверные приложения пригодны только в простых предметных областях?
Во-вторых, как мы неоднократно подчеркивали в первой части курса, необходимыми требованиями к базе данных информационной системы являются поддержание ее целостного состояния и гарантированная надежность хранения информации. Минимальными условиями, при соблюдении которых можно удовлетворить эти требования, являются:
- наличие транзакционного управления, хранение избыточных данных (например, с применением методов журнализации), возможность формулировать ограничения целостности и проверять их соблюдение.
В принципе, файл-серверная организация, как она показана на рисунке 2.1, не противоречит соблюдению отмеченных условий. В качестве примера системы, соблюдающей выполнение этих условий, но основанной на файл-серверной архитектуре, можно привести популярный в прошлом "сервер баз данных" Informix SE.
Длинноезамечание:
Для сохранения четкости дальнейшего изложения нам необходимо несколько уточнить терминологию. Мы недаром написали "сервер баз данных" в кавычках применительно к СУБД Informix SE. При использовании этой системы копия программного обеспечения СУБД поддерживалась для каждого инициированного пользователем сеанса работы с СУБД. Грубо говоря, для каждого пользовательского процесса, взаимодействующего с базой данных создавался служебный процесс СУБД, который выполнялся на том же процессоре, что и пользовательский процесс (т. е. на стороне клиента). Каждый из этих служебных процессов вел себя фактически так, как если бы был единственным представителем СУБД. Вся синхронизация возможной параллельной работы с базой данных производилась на уровне файлов внешней памяти, содержащих базу данных. Условимся впредь называть такие СУБД не серверами баз данных, а системами управления базами данных, основанными на файл-серверной архитектуре (СУБД-ФС).
Под истинным сервером баз данных мы будем понимать программное образование, привязанное к соответствующей базе (базам) данных, существующее, вообще говоря, независимо от существования пользовательских (клиентских) процессов и выполняемое, вообще говоря (хотя и не обязательно) на выделенной аппаратуре (мы намеренно используем не очень конкретные термины "программное образование" и "выделенная аппаратура", потому что их конкретное воплощение различается в разных серверах баз данных).
Истинные серверы баз данных существенно сложнее по организации, чем СУБД-ФС, на зато обеспечивают более тонкое и эффективное управление базами данных. Везде далее в этом курсе при употреблении термина "сервер баз данных" мы будем иметь в виду истинные серверы баз данных.
Но с другой стороны, в большинстве персональных СУБД эти условия не выполняются даже с помощью грубых приемов. В лучшем случае удается частично восполнить недостатки на уровне прикладных программ.
В третьих, интерфейс развитых серверов баз данных основан на использовании высокоуровневого языка баз данных SQL, что позволяет использовать сетевой трафик между клиентом и сервером баз данных только в полезных целях (от клиента к серверу в основном пересылаются операторы языка SQL, от сервера к клиенту - результаты выполнения операторов). В файл-серверной организации клиент работает с удаленными файлами, что вызывает существенную перегрузку трафика (поскольку СУБД-ФС работает на стороне клиента, то для выборки полезных данных в общем случае необходимо просмотреть на стороне клиента весь соответствующий файл целиком).
В целом, в файл-серверной архитектуре мы имеем "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти (рисунок 2.2).

Рис. 2.2. "Толстый" клиент и "тонкий" сервер в файл-серверной архитектуре
Краткие выводы. Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение можно спроектировать, разработать и отладить очень быстро. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Конечно, и в этом случае требуется большая аккуратность конечных пользователей (или администраторов, наличие которых в этом случае сомнительно) для надежного хранения и поддержания целостного состояния данных. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными.
Клиент-серверные приложения
Под клиент-серверным приложением мы будем понимать информационную систему, основанную на использовании серверов баз данных (см. длинное замечание в конце раздела 2.1). Общее представление информационной системы в архитектуре "клиент-сервер" показано на рисунке 2.3.
- На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции (пока нас не будет занимать, как строится код приложения). Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения.
(Здесь опять проявляются недостатки в терминологии. Обычно, когда компания объявляет о выпуске очередного сервера баз данных, то неявно понимается, что имеется и клиентская составляющая этого продукта. Сочетание "клиентская часть сервера баз данных" кажется несколько странным, но нам придется пользоваться именно этим термином.)

Рис. 2.3. Общее представление информационной системы в архитектуре "клиент-сервер"
Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения.
Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Здесь необходимо сделать еще два замечания.
Обычно компании, производящие развитые серверы баз данных, стремятся к тому, чтобы обеспечить возможность использования своих продуктов не только в стандартных на сегодняшний день TCP/IP-ориентированных сетях, но в сетях, основанных на других протоколах (например, SNA или IPX/SPX). Поэтому при организации сетевых взаимодействий между клиентской и серверной частями СУБД часто используются не стандартные средства высокого уровня (например, механизмы программных гнезд или вызовов удаленных процедур), а собственные функционально подобные средства, менее зависящие от особенностей сетевых транспортных протоколов. Когда мы говорим об интерфейсе на основе языка SQL, нужно отдавать себе отчет в том, что несмотря на титанические усилия по стандартизации этого языка, нет такой реализации, в которой стандартные средства языка не были бы расширены. Необдуманное использование расширений языка приводит к полной зависимости приложения от конкретного производителя сервера баз данных.
Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL.
- Сервер производит компиляцию полученного оператора. Не будем здесь останавливаться на том, какой целевой язык используется конкретным компилятором; в разных реализациях применяются различные подходы (примеры см. в части 4). Главное, что в любом случае на основе информации, содержащейся в таблицах-каталогах базы данных производится преобразование непроцедурного представления оператора в некоторую процедуру его выполнения. Далее (если компиляция завершилась успешно) происходит выполнение оператора. Мы снова не будем обсуждать технические детали, поскольку они различаются в реализациях. Рассмотрим возможные действия операторов SQL.
- Оператор может относиться к классу операторов определения (или создания) объектов базы данных (точнее и правильнее было бы говорить про элементы схемы базы данных или про объекты метабазы данных). В частности, могут определяться домены, таблицы, ограничения целостности, триггеры, привилегии пользователей, хранимые процедуры. В любом случае, при выполнении оператора создания элемента схемы базы данных соответствующая информация помещается в таблицы-каталоги базы данных (в таблицы метабазы данных). Ограничения целостности обычно сохраняются в метабазе данных прямо в текстовом представлении. Для действий, определенных в триггерах, и хранимых процедур вырабатывается и сохраняется в таблицах-каталогах процедурный выполняемый код. Заметим, что ограничения целостности, триггеры и хранимые процедуры являются, в некотором смысле, представителями приложения в поддерживаемой сервером базе данных; они составляют основу серверной части приложения (см. ниже). При выполнении операторов выборки данных на основе содержимого затрагиваемых запросом таблиц и, возможно, с использованием поддерживаемых в базе данных индексов формируется результирующий набор данных (мы намеренно не используем здесь термин "результирующая таблица", поскольку в зависимости от конкретного вида оператора результат может быть упорядоченным, а таблицы, т. е. отношения неупорядочены по определению). Серверная часть СУБД пересылает результат клиентской части, и окончательная обработка производится уже в клиентской части приложения. При выполнении операторов модификации содержимого базы данных (INSERT, UPDATE, DELETE) проверяется, что не будут нарушены определенные к этому моменту ограничения целостности (те, которые относятся к классу немедленно проверяемых), после чего выполняется соответствующее действие (сопровождаемое модификацией всех соответствующих индексов и журнализацией изменений). Далее сервер проверяет, не затрагивает ли данное изменение условие срабатывания какого-либо триггера, и если такой триггер обнаруживается, выполняет процедуру его действия. Эта процедура может включать дополнительные операторы модификации базы данных, которые могут вызвать срабатывание других триггеров и т. д. Можно считать, что те действия, которые выполняются на сервере баз данных при проверке удовлетворенности ограничений целостности и при срабатывании триггеров, представляют собой действия серверной части приложения. При выполнении операторов модификации схемы базы данных (добавления или удаления столбцов существующих таблиц, изменения типа данных существующего столбца существующей таблицы и т. д.) также могут срабатывать триггеры, т. е., другими словами, может выполняться серверная часть приложения. Аналогично, триггеры могут срабатывать при уничтожении объектов схемы базы данных (доменов, таблиц, ограничений целостности и т. д.). Особый класс операторов языка SQL составляют операторы вызова ранее определенных и сохраненных в базе данных хранимых процедур. Если хранимая процедура определяется с помощью достаточно развитого языка, включающего и непроцедурные операторы SQL, и чисто процедурные конструкции (например, языка PL/SQL компании Oracle), то в такую процедуру можно поместить серьезную часть приложения, которое при выполнении оператора вызова процедуры будет выполняться на стороне сервера, а не на стороне клиента. При выполнении оператора завершения транзакции сервер должен проверить соблюдение всех, так называемых, отложенных ограничений целостности (к таким ограничениям относятся ограничения, накладываемые на содержимое таблицы базы целиком или на несколько таблиц одновременно; например, суммарная зарплата сотрудников отдела 999 не должна превышать 150 млн. руб.). Снова к проверке отложенных ограничений целостности можно относиться как к выполнению серверной части приложения.
Как видно, в клиент-серверной организации клиенты могут являться достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов (рисунок 2.4).

Рис. 2.4. "Тонкий" клиент и "толстый" сервер в клиент-серверной архитектуре
С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами , которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента.
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных (или, как иногда их называют в русскоязычной литературе, тиражированных) баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных - упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа. Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения - от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. В любом случае, клиенты становятся более толстыми при том, что сервер тоньше не делается (рисунок 2.5).

Рис. 2.5. "Потолстевший" клиент и "толстый" сервер в клиент-серверной архитектуре с поддержкой локального кэша на стороне клиентов
Сформулируем некоторые предварительные выводы. Архитектура "клиент-сервер" на первый взгляд кажется гораздо более дорогой, чем архитектура "файл-сервер". Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления базами данных. Однако, это верно лишь частично. Громадным преимуществом клиент-серверной архитектуры является ее масштабируемость и вообще способность к развитию.
При проектировании информационной системы, основанной на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике.
Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. В идеале, которого, конечно же не бывает, информационная система продолжает нормально функционировать после смены аппаратуры.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
[Введите текст]
Серверы. Основные понятия серверов
Модель клиент-сервер
Классификация стандартных серверов
Список использованной литературы
Серверы. Основные понятия серверов
Сервер (от англ. server, обслуживающий). В зависимости от предназначения существует несколько определений понятия сервер.
1. Сервер (сеть) - логический или физический узел сети, обслуживающий запросы к одному адресу и/или доменному имени (смежным доменным именам), состоящий из одного или системы аппаратных серверов, на котором выполняются один или система серверных программ
2. Сервер (программное обеспечение) - программное обеспечение, принимающее запросы от клиентов (в архитектуре клиент-сервер).
3. Сервер (аппаратное обеспечение) - компьютер (или специальное компьютерное оборудование) выделенный и/или специализированный для выполнения определенных сервисных функций.
3. Сервер в информационных технологиях - программный компонент вычислительной системы, выполняющий сервисные функции по запросу клиента, предоставляя ему доступ к определённым ресурсам.
Взаимосвязь понятий. Серверное приложение (сервер) запускается на компьютере, так же называемом "сервер", при этом при рассмотрении топологии сети, такой узел называют "сервером". В общем случае может быть так, что серверное приложение запущено на обычной рабочей станции, или серверное приложение, запущенное на серверном компьютере в рамках рассматриваемой топологии выступает в роли клиента (т.е. не является сервером с точки зрения сетевой топологии).
Модель клиент-сервер
Понятия сервер и клиент и закрепленные за ними роли образуют программную концепцию «клиент-сервер». Модель клиент-сервер - это еще один подход к структурированию Операционной системы (ОС). В широком смысле модель клиент-сервер предполагает наличие программного компонента - потребителя какого-либо сервиса - клиента, и программного компонента - поставщика этого сервиса - сервера. Взаимодействие между клиентом и сервером стандартизуется, так что сервер может обслуживать клиентов, реализованных различными способами и, может быть, разными производителями. При этом главным требованием является то, чтобы они запрашивали услуги сервера понятным ему способом. Инициатором обмена обычно является клиент, который посылает запрос на обслуживание серверу, находящемуся в состоянии ожидания запроса. Один и тот же программный компонент может быть клиентом по отношению к одному виду услуг, и сервером для другого вида услуг. Модель клиент-сервер является скорее удобным концептуальным средством ясного представления функций того или иного программного элемента в той или иной ситуации, нежели технологией. Эта модель успешно применяется не только при построении ОС, но и на всех уровнях программного обеспечения, и имеет в некоторых случаях более узкий, специфический смысл, сохраняя, естественно, при этом все свои общие черты. Применительно к структурированию ОС идея состоит в разбиении ее на несколько процессов - серверов, каждый из которых выполняет отдельный набор сервисных функций - например, управление памятью, создание или планирование процессов. Каждый сервер выполняется в пользовательском режиме. Клиент, которым может быть либо другой компонент ОС, либо прикладная программа, запрашивает сервис, посылая сообщение на сервер. Ядро ОС (называемое здесь микроядром), работая в привилегированном режиме, доставляет сообщение нужному серверу, сервер выполняет операцию, после чего ядро возвращает результаты клиенту с помощью другого сообщения. Для взаимодействия с клиентом (или клиентами, если поддерживается одновременная работа с несколькими клиентами) сервер выделяет необходимые ресурсы межпроцессного взаимодействия (разделяемая память, пайп, сокет, и т. п.) и ожидает запросы на открытие соединения (или, собственно, запросы на предоставляемый сервис). В зависимости от типа такого ресурса, сервер может обслуживать процессы в пределах одной компьютерной системы или процессы на других машинах через каналы передачи данных (например, COM-порт) или сетевые соединения.
Формат запросов клиента и ответов сервера определяется протоколом. Спецификации открытых протоколов описываются открытыми стандартами, например, протоколы Интернета определяются в документах RFC.
В зависимости от выполняемых задач одни серверы, при отсутствии запросов на обслуживание, могут простаивать в ожидании. Другие могут выполнять какую-то работу (например, работу по сбору информации), у таких серверов работа с клиентами может быть второстепенной задачей.
Классификация стандартных серверов
Как правило, каждый сервер обслуживает один (или несколько схожих) протоколов и серверы можно классифицировать по типу услуг, которые они предоставляют.
Универсальные серверы - особый вид серверной программы, не предоставляющий никаких услуг самостоятельно. Вместо этого универсальные серверы предоставляют серверам услуг упрощенный интерфейс к ресурсам межпроцессного взаимодействия и/или унифицированный доступ клиентов к различным услугам. Существуют несколько видов таких серверов:
inetd от англ. internet super-server daemon демон сервисов IP - стандартное средство UNIX-систем - программа, позволяющая писать серверы TCP/IP (и сетевых протоколов других семейств), работающие с клиентом через перенаправленные inetd потоки стандартного ввода и вывода (stdin и stdout).
RPC от англ. Remote Procedure Call удаленный вызов процедур - система интеграции серверов в виде процедур доступных для вызова удаленным пользователем через унифицированный интерфейс. Интерфейс изобретенный Sun Microsystems для своей операционной системы (SunOS, Solaris; Unix-система), в настоящее время используетстся как в большинстве Unix-систем, так и в Windows.
Прикладные клиент-серверные технологии Windows:
(D-)COM (англ. (Distributed) Component Object Model - модель составных объектов) и др. - Позволяет одним программам выполнять операции над объектами данных используя процедуры других программ. Изначально данная технология предназначена для их «внедрения и связывания объектов» (OLE англ. Object Linking and Embedding), но, в общем, позволяет писать широкий спектр различных прикладных серверов. COM работает только в пределах одного компьютера, DCOM доступна удаленно через RPC.
Active-X - Расширение COM и DCOM для создания мультимедиа-приложений.
Универсальные серверы часто используются для написания всевозможных информационных серверов, серверов, которым не нужна какая-то специфическая работа с сетью, серверов, не имеющих никаких задач, кроме обслуживания клиентов. Например, в роли серверов для inetd могут выступать обычные консольные программы и скрипты.
Большинство внутренних и сетевых специфических серверов Windows работают через универсальные серверы (RPC, (D-)COM).
Сетевые службы обеспечивают функционирование сети, например серверы DHCP и BOOTP обеспечивают стартовую инициализацию серверов и рабочих станций, DNS - трансляцию имен в адреса и наоборот.
Серверы туннелирования (например, различные VPN-серверы) и прокси-серверы обеспечивают связь с сетью, недоступной роутингом.
Серверы AAA и Radius обеспечивают в сети единую аутентификацию, авторизацию и ведение логов доступа.
Информационные службы. К информационным службам можно отнести как простейшие серверы сообщающие информацию о хосте (time, daytime, motd), пользователях (finger, ident), так и серверы для мониторинга, например SNMP. Большинство информационных служб работают через универсальные серверы.
Особым видом информационных служб являются серверы синхронизации времени - NTP кроме информировании клиента о точном времени NTP-сервер периодически опрашивает несколько других серверов на предмет коррекции собственного времени. Кроме коррекции времени анализируется и корректируется скорость хода системных часов. Коррекция времени осуществляется ускорением или замедлением хода системных часов (в зависимости от направления коррекции), чтобы избежать проблем возможных при простой перестановке времени.
Файл-серверы представляют собой серверы для обеспечения доступа к файлам на диске сервера.
Прежде всего, это серверы передачи файлов по заказу, по протоколам FTP, TFTP, SFTP и HTTP. Протокол HTTP ориентирован на передачу текстовых файлов, но серверы могут отдавать в качестве запрошенных файлов и произвольные данные, например, динамически созданные веб-страницы, картинки, музыку и т. п.
Другие серверы позволяют монтировать дисковые разделы сервера в дисковое пространство клиента и полноценно работать с файлами на них. Это позволяют серверы протоколов NFS и SMB. Серверы NFS и SMB работают через интерфейс RPC.
Недостатки файл-серверной системы:
Очень большая нагрузка на сеть, повышенные требования к пропускной способности. На практике это делает практически невозможной одновременную работу большого числа пользователей с большими объемами данных.
Обработка данных осуществляется на компьютере пользователей. Это влечет повышенные требования к аппаратному обеспечению каждого пользователя. Чем больше пользователей, тем больше денег придется потратить на оснащение их компьютеров.
Блокировка данных при редактировании одним пользователем делает невозможной работу с этими данными других пользователей.
Безопасность. Для обеспечения возможности работы с такой системой Вам будет необходимо дать каждому пользователю полный доступ к целому файлу, в котором его может интересовать только одно поле
Серверы доступа к данным обслуживают базу данных и отдают данные по запросам. Один из самых простых серверов подобного типа - LDAP (англ. Lightweight Directory Access Protocol - облегчённый протокол доступа к спискам).
Для доступа к серверам баз данных единого протокола не существует, однако все серверы баз данных объединяет использование единых правил формирования запросов - язык SQL (англ. Structured Query Language - язык структурированных запросов).
Службы обмена сообщениями позволяют пользователю передавать и получать сообщения (обычно - текстовые).
В первую очередь это серверы электронной почты, работающие по протоколу SMTP. SMTP-сервер принимает сообщение и доставляет его в локальный почтовый ящик пользователя или на другой SMTP-сервер (сервер назначения или промежуточный). На многопользовательских компьютерах, пользователи работают с почтой прямо на терминале (или веб-интерфейсе). Для работы с почтой на персональном компьютере, почта забирается из почтового ящика через серверы, работающие по протоколам POP3 или IMAP.
Для организации конференций существует серверы новостей, работающие по протоколу NNTP.
Для обмена сообщениями в реальном времени существуют серверы чатов, стандартный чат-сервер работает по протоколу IRC - распределенный чат для интернета.
Существует большое количество других чат-протоколов, например ICQ или Jabber.
Серверы удаленного доступа
Серверы удаленного доступа, через соответствующую клиентскую программу, обеспечивают пользователя консольным доступом к удаленной системе.
Для обеспечения доступа к командной строке служат серверы telnet, RSH, SSH.
Графический интерфейс для Unix-систем - X Window System, имеет встроенный сервер удаленного доступа, так как с такой возможностью разрабатывался изначально. Иногда возможность удаленного доступа к интерфейсу Х-Window неправильно называют «X-Server» (этим термином в X-Window называется видеодрайвер).
Стандартный сервер удаленного доступа к графическому интерфейсу Microsoft Windows называется терминальный сервер.
Некоторую разновидность управления (точнее мониторинга и конфигурирования), также, предоставляет протокол SNMP. Компьютер или аппаратное устройство для этого должно иметь SNMP-сервер.
Игровые серверы, служат для одновременной игры нескольких пользователей в единой игровой ситуации. Некоторые игры имеют сервер в основной поставке и позволяют запускать его в невыделенном режиме (то есть позволяют играть на машине, на которой запущен сервер).
Серверные решения - операционные системы и/или пакеты программ, оптимизированные под выполнение компьютером функций сервера и/или содержащие в своем составе комплект программ для реализации типичного сервисов.
Примером серверных решений можно привести Unix-системы, изначально предназначенные для реализации серверной инфраструктуры, или серверные модификации платформы Microsoft Windows.
Также необходимо выделить пакеты серверов и сопутствующих программ (например, комплект веб-сервер/PHP/MySQL для быстрой развертки хостинга) для установки под Windows (для Unix свойственна модульная или «пакетная» установка каждого компонента, поэтому такие решения редки).
В интегрированных серверных решениях установка всех компонентов выполняется единовременно, все компоненты в той или иной мере тесно интегрированы и предварительно настроены друг на друга. Однако в этом случае, замена одного из серверов или вторичных приложений (если их возможности не удовлетворяют потребностям) может представлять проблему.
Серверные решения служат для упрощения организации базовой ИТ-инфраструктуры компаний, то есть для оперативного построения полноценной сети в компании, в том числе и «с нуля». Компоновка отдельных серверных приложений в решение подразумевает, что решение предназначено для выполнения большинства типовых задач; при этом значительно снижается сложность развертывания и общая стоимость владения ИТ-инфраструктурой, построенной на таких решениях.
Прокси-сервер (от англ. proxy - «представитель, уполномоченный») служба в компьютерных сетях, позволяющая клиентам выполнять косвенные запросы к другим сетевым службам. Сначала клиент подключается к прокси-серверу и запрашивает какой-либо ресурс (например, e-mail), расположенный на другом сервере. Затем прокси-сервер либо подключается к указанному серверу и получает ресурс у него, либо возвращает ресурс из собственного кеша (в случаях, если прокси имеет свой кеш). В некоторых случаях запрос клиента или ответ сервера может быть изменён прокси-сервером в определённых целях. Также прокси-сервер позволяет защищать клиентский компьютер от некоторых сетевых атак.
Вывод ы
сервер формат п рокси windows
Таким образом, любая компьютерная сеть, по сути, является сетью клиент-сервер. Пользователь, подключивший свой компьютер к Интернет, будет иметь дело с сетью клиент-сервер, и даже если компьютер не имеет выхода в сеть, его программное обеспечение, да и сам он, скорее всего, организованы по схеме клиент-сервер.
Список использ ованной литературы
1. Дрога А.А., Жукова П.Н., Копонев Д.Н., Лукьянов Д.Б., Прокопенко А.Н. Информатика и математика. - Минск, 2008.
2. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика - 3-е изд. - М.: «Вильямс», 2003.
3. Кузнецов С.Д. Основы баз данных. - 1-е изд. - М.: «Интернет- университет информационных технологий - ИНТУИТ.ру», 2005.
4. Скотт В. Эмблер, Прамодкумар Дж. Садаладж. Рефакторинг баз данных: эволюционное проектирование - М.: «Вильямс», 2007.
5. А.Н. Морозевич, А.М. Зеневич Информатика. Минск, 2008.
6.Титоренко Г.А. Информационные технологии управления. М., Юнити: 2002.
7. Мельников В. Защита информации в компьютерных системах. - М.: Финансы и статистика, Электронинформ, 1997.
Размещено на Allbest.ru
...Подобные документы
Основные понятия серверов. Модель клиент-сервер. Классификация стандартных серверов. Недостатки файл-серверной системы. Криптографические методы защиты информации. Серверы удаленного доступа. Методы и средства обеспечения безопасности информации.
контрольная работа , добавлен 13.12.2010
Общие сведения об операционной системе Linux. Анализ информации о серверах. Основные прикладные клиент-серверные технологии Windows. Сведения о SQL-сервере. Общая информация о MySQL–сервере. Установка и специфика конфигурирования MYSQL-сервера на LINUX.
курсовая работа , добавлен 16.12.2015
Анализ архитектуры информационной системы, в структуру которой входят системы файл-сервер и клиент-сервер. Сравнение языков запросов SQL и QBE. Принципы разработки приложений архитектуры клиент-сервер при помощи структурированного языка запросов SQL.
курсовая работа , добавлен 11.04.2010
Архитектура "клиент-сервер". Системный анализ базы данных "Газета объявлений", ее инфологическое и физическое проектирование. Программирование на стороне SQL-сервера. Разработка клиентской части в Borland C++ Builder 6.0 и с помощью Web-технологий.
курсовая работа , добавлен 07.07.2013
Методика и основные этапы разработки системы тестирования для оценки уровня знаний студентов с применением технологии "Клиент-сервер". Проектирование клиентской, серверной части данной системы тестирования, порядок составления финальных отчетов.
дипломная работа , добавлен 08.11.2010
Проектирование физической и логической моделей удаленной базы данных для АЗС. Разработка базы данных в СУБД Firebird с помощью утилиты IBExpert. Создание клиентского приложения для Windows с использованием клиент-серверной технологии в среде C++ Builder.
курсовая работа , добавлен 18.01.2017
Создание программного продукта на основании клиент-серверной технологии, реализующего отказоустойчивую работу системы, которая способна в случае потери связи с ведущим сервером подключить клиента к альтернативному серверу (на примере сервера погоды).
курсовая работа , добавлен 24.08.2012
Проектирование и разработка базы данных в РСУБД Firebird. Последовательность создания приложения, основанного на клиент-серверной технологии и работающего в операционной системе Windows. Хранимые процедуры и триггеры. Доступ к сети и транзакции.
курсовая работа , добавлен 27.07.2013
Реляционные базы данных как часть корпоративных информационных систем, их построение по принципам клиент-серверной технологии. Основные характеристики СУБД Firebird. Проектирование базы данных для информационной системы "Компьютерные комплектующие".
курсовая работа , добавлен 28.07.2013
Архитектура "клиент-сервер". Параллельная обработка данных в многопроцессорных системах. Модернизация устаревших информационных систем. Характерные черты современных серверных СУБД. Наиболее популярные серверные СУБД. Распределенные запросы и транзакции.
Использование технологии «клиент-сервер»
Со временем не очень функциональную модель файлового сервера для локальных сетей (FS) сменили появившиеся одна задругой модели строения «Клиент сервер» (RDA, DBS и AS).
Технология «Клиент - сервер», которая заняла самый низ базы данных, стала главной технологией глобальной сети Internet. Далее, вследствие перенесения идей сети Internet в сферу корпоративных систем, возникла технология Intranet. В различие от технологии «Клиент-сервер» такая технология обращена на информацию в ее окончательно готовом виде к потреблению, а не на данные. Вычислительные системы, которые построенны на основе Intranet, обладают в своем составе центральные серверы информации и определенные компоненты представления информации последнему пользователю (браузеры или программы-навигаторы). Дейсвие между сервером и клиентом в Intranet совершается с помощью web - технологий.
В современное время технология «Клиент-сервер» приобрела очень значительное распространение, но сама по себе данная технология универсальных рецептов не имеет. Она только доставляет всеобщее суждение о том, как должна быть создана нынешняя распределительная информационная система. Так же осуществления этой технологии в определенных программных товарах и даже в видах программного обеспечения распознаются весьма существенно.
Классическая двухуровневая архитектура «Клиент - сервер»
Как правило компоненты сети не имеют равных прав: у одних есть доступ к ресурсам (например: система управления базами данных, процессор, принтер, файловая система и прочие), у других есть возможность обращаться к этим ресурсам. операционный система сервер технология
Технология «Клиент - сервер» - это архитектура программного комплекса распределяющая прикладной программой по двум логически различным частям (сервер и клиент), которые взаимодействуют по схеме «запрос-ответ» и решают собственные определенные задачи.
Программа (или компьютер), управляющая и/или владеющая каким-нибудь ресурсом, называется сервером этого ресурса.
Программа (компьютер или), запрашивающая и пользующаяся каким-либо ресурсом, называется клиентом этого ресурса.
При этом так же может появиться такое условия, когда кое-какой программный блок будет одновременно реализовывать функции сервера по отношению к одному блоку и клиента по отношению к другому блоку.
Главный принцип технологии «Клиент-сервер» заключается в разделении функций приложения как минимум на три звена:
Модули интерфейса с пользователем;
Еще эта группа называется логикой представления. С ее помощью пользователи могут взаимодействовать с приложениями. Независимо от конкретных характеристик логики представления (интерфейс командной строки,интерфейсы через посредника, сложные графические пользовательские интерфейсы) ее задача заключается в том, чтобы обеспечить средства для большей эффективности обмена информацией между информационной системой и пользователем.
Модули хранения данных;
Эта группа еще называется бизнес-логикой. Бизнес-логика находит, для чего именно нужно то или иное приложение (например, прикладные функции, присущие для предоставленной предметной области). Разделение приложения по границам между программами обеспечивает натуральную основу для распределения приложения на двух или более компьютерах.
Модули обработки данных (функции управления ресурсами);
Так же эта группа называется логикой алгоритмами доступа к данным или просто доступа к данным. Алгоритмы входа к данным рассматриваются как специфический интерфейс для конкретного приложения к устройству стабильного сохранения данных наподобие СУБД или же файловой системы. С помощью модулей обработки данных организуется специфический интерфейс для приложения СУБД. С помощью интерфейса приложение может управлять соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных). Каждое из перечисленных звеньев может реализоваться независимо от нескольких других. Например, не изменяя программ, которые используются для обработки и хранения данных, можно изменить интерфейс с пользователем так, что одни и те же данные будут отображаться в виде таблиц, гистограмм или же графиков. Самые простые приложения часто способны собрать все три звена в единственную программу, и подобное разделение соответствует функциональным границам.
В соответствии с разделением функций в каждом приложении выделяют следующие компоненты:
- - компонент представления данных;
- - прикладной компонент;
- - компонент управления ресурсом.
Клиент-сервер в классической архитектуре нужно распределить три главные части приложения по 2-м физическим модулям. Обычно прикладной компонент находится на сервере (например, на сервере БД), компонент представления данных - на стороне клиента, а компонент управления ресурсом распределяется между серверной и клиентской частями. В этом заключается главный недостаток классической двухуровневой архитектуры.
В двухзвенной архитектуре при разделении алгоритмов обработки данных, разработчики должны иметь полную информацию о последних изменениях, которые были внесены в систему, и понимать эти изменения, что создает не маленькие сложности при разработке клиент-серверных систем, их сопровождении и установке, поскольку необходимо тратить большие усилия на координацию действий разных групп специалистов. В действиях разработчиков часто возникают противоречия, а это тормозит развитие системы и вынуждает изменять уже готовые и проверенные элементы.
Чтобы избежать несогласованности разных элементов архитектуры, создали две модификации двухзвенной архитектуры «Клиент - сервер»: «Толстый клиент» («Тонкий сервер») и «Тонкий клиент» («Толстый сервер»).
В этой архитектуре разработчики попытались выполнять обработку данных на одной из двух физических частей - либо на стороне клиента («Толстый клиент»), либо на сервере («Тонкий клиент).
У каждого подхода есть свои значительные недостатки. В первой ситуации неоправданно перегружается сеть, потому что по ней передаются необработанные то есть избыточные данные. Кроме того, усложняется поддержка системы и ее изменение, потому что исправление ошибки или же замена алгоритма вычислений требуют одновременной полной замены всех интерфейсных программ, если не сделать полной замены, то может возникнуть несогласованность данных или ошибки. Если же вся обработка информации выполняется на сервере, то возникает проблема описания встроенных процедур и их отладки. Систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу (ОС), это является серьезным недостатком.
Если же создается двухуровневая классическая архитектура «Клиент - сервер», то нужно знать следующие факты:
Архитектура «Толстый сервер» аналогична архитектуре «Тонкий клиент»
Передача запроса от клиента на сервер, обработка запроса сервером и передача результата клиенту. При этом архитектуры имеют следующие недостатки:
- - усложняется реализация, так как языки типа SQL не приспособлены для разработки подобного ПО и нет хороших средств отладки;
- - производительность программ, которые написаны на языках типа SQL, очень низка, чем созданые на прочих языках, что имеет наиболее важное значение для сложных систем;
- - программы, которые написаны на СУБД-языках как правило функционируют от части не очень надежно; ошибка в них может привести к выходу из строя всего сервера баз данных;
- - получившиеся таким образом программы полностью непереносимы на другие платформы и системы.
- - архитектура «Толстый клиент» аналогична архитектуре «Тонкий сервер»
Обработка запроса совершается на стороне клиента, то есть совершается передача клиенту всех необработанных данных с сервера. В этом случае у архитектур имеются негативные стороны:
- - усложняется обновление ПО, потому что его замену нужно производить одновременно по всей системе;
- - усложняется распределение полномочий, потому что разграничение доступа происходит не по действиям, а по таблицам;
- - перегружается сеть вследствие передачи по ней необработанных данных;
- - слабая защита данных, так как сложно правильно распределить полномочия.
Для решения перечисленных проблем нужно использовать многоуровневые (три и более уровней) архитектуры «Клиент-сервер».
Трехуровневая модель .
С середины 90-х годов прошлого века популярность специалистов получила трехзвенная архитектура «Клиент - сервер», разделившая информационную систему по функциональным возможностям на три некоторых звена: логика доступа к данным, логика представления и бизнес-логика. В противоположность двухуровневой архитектуры в трехуровневой имеется дополнительное звено - сервер приложений, предназначенный для осуществления бизнес-логики, при этом полностью разгружается клиент, который посылает запросы промежуточному программному обеспечению, и максимально употребляются все возможности серверов.
В трехуровневой архитектуре клиент как правило не перегружен функциями обработки данных, а осуществляет свою главную роль системы представления информации, поступающей с сервера приложений. Такой интерфейс можно привести в исполнение с помощью стандартных средств Web-технологии - браузера, CGI и Java. Это понижает объемность данных, предоставляемых между клиентом и сервером приложений, что позволяет подключать клиентские компьютеры даже по медленным линиям типа телефонных каналов. В связи с этим, клиентская часть может быть такой простой, что в большинстве случаев ее осуществляют с помощью универсального браузера. Однако если все-таки ее поменять придется, то эту процедуру можно реализовать быстро и безболезненно.
Сервер приложений - это программное обеспечение, которое является промежуточным пластом между сервером и клиентом.
- - Message orientated - яркие представители MQseries и JMS;
- - Object Broker - яркие представители CORBA и DCOM;
- - Component based - яркие представители.NET и EJB.
Применение сервера приложений приносит намного больше возможностей, например, снижается нагрузка на клиентские компьютеры, так как сервер приложений распределяет нагрузку и обеспечивает защиту от сбоев. Поскольку бизнес-логика хранится на сервере приложений, то при каких-либо изменениях в отчетности или расчетах клиентские программы никаким образом не задеваются.
Есть немного серверов приложений от таких знаменитых компаний как Sun, Oracle Microsystem, IBM, Borland и каждый из них различается комплектом предоставляемых сервисов (производительность учитывать в данном случае не буду). Эти сервисы облегчают программирование и развертывание приложений масштаба предприятия. Как правило сервер приложений дает следующие сервисы:
- - WEB Server - чаще всего включают в поставку самый мощный и популярный Apache;
- - WEB Container - позволяет выполнять JSP и сервлеты. Для Apache таким сервисом является Tomcat;
- - CORBA Agent - может предоставлять распределенную директорию для хранения CORBA объектов;
- - Messaging Service - брокер сообщений;
- - Transaction Service - уже из названия понятно, что это сервис транзакций;
- - JDBC - драйвера для подключения к базам данных, ведь именно серверу приложений придется общаться с базами данных и ему нужно уметь подключаться к используемой в вашей компании базе;
- - Java Mail - данный сервис может предоставлять сервис к SMTP;
- - JMS (Java Messaging Service) - обработка синхронных и асинхронных сообщений;
- - RMI (Remote Method Invocation) - вызов удаленных процедур.
Многоуровневые клиент-серверные системы довольно легко можно перевести на Web-технологию - для этого нужно заменить клиентскую часть специализированным или универсальным браузером, а сервер приложений дополнить Web-сервером и малыми программами вызова процедур сервера. Для
разработки этих программ можно употребить как Common Gateway Interface (CGI), так и более современную технологию Java.
В трехуровневой системе в качестве каналов связи между сервером приложений и СУБД можно использовать наиболее быстрые линии, требующие минимальныхзатрат, так как сервера как правило находятся в одном помещении (серверной) и не будет перегружать сеть из-за передачи высокого количества информации.
Из всего перечисленного вытекает вывод о том, что двухуровневая архитектура весьма уступает многоуровневой архитектуре, в связи с этим на сегодняшний день применяется только многоуровневая архитектура «Клиент - сервер», распознающая три модификации - RDA, DBS и AS.
Различные модели технологии «Клиент - сервер»
Самой первой основной базовой технологией для локальных сетей была модель файлового сервера (FS) . В то время эта технология была весьма распространена среди отечественных разработчиков, использовавших такие системы, как FoxPro, Clipper, Clarion, Paradox и так далее.
В модели FS функции всех 3-х компонентов (компонент представления, прикладной компонент и компонент доступа к ресурсам) совмещены в одном коде, который осуществляется на компьютере-сервере (хосте). Компьютер-клиент в такой архитектуре совсем отсутствует, а отображение и вынесение данных совершается с помощью компьютера компьютера или терминала в порядке эмуляции терминала. Приложения обычно формируются на языке четвертого поколения (4GL). Один из компьютеров в сети считается файловым сервером и дает другим компьютерам услуги по обработке файлов. Он функционирует под управлением сетевых ОС и играет важную роль компонента доступа к информационным ресурсам. На прочих ПК в сети функционирует приложение, в кодах которого соединены прикладной компонент и компонент представления.
Технология действия между клиентом и сервером такая: запрос посылается на файловый сервер, передающий СУБД, которая размещена на компьютере-клиенте, требуемый блок данных. Вся обработка исполняется на терминале.
Протокол обмена - это некий набор вызовов, которые обеспечивают приложению вход к файловой системе на файл-сервере.
Положительными сторонами данной технологии являются:
- - простота разработки приложений;
- - удобство администрирования и обновления ПО
- - низкая стоимость оборудования рабочих мест (терминалы или дешевые компьютеры с низкими характеристиками в режиме эмуляции терминала всегда дешевле полноценных ПК).
Но достоинства FS - модели превосходят ее недостатки:
Несмотря на немаленький объем данных, которые пересылаются по сети, время отклика является критичным, потому что каждый символ, введенный клиентом на терминале, должен быть передан на сервер, обработан приложением и возвращен обратно для вывода на экран терминала. Помимо этого существует проблема распределения нагрузки между несколькими компьютерами.
- - дорогостоящее аппаратное обеспечение сервера , так как все пользователи разделяют его ресурсы;
- - отсутствие графического интерфейса .
Благодаря решению проблем, присущих технологии «Файл - сервер» появилась более прогрессивная технология, получившая название «Клиент - сервер».
Для современных СУБД архитектура «клиент-сервер» стала фактически стандартом. Если предполагается, что проектируемая сетевая технология будет иметь архитектуру «клиент-сервер», то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер, то есть часть функций приложений будет реализована в программе-клиенте, другая - в программе-сервере.
Различия в реализации приложений в рамках технологии «Клиент-сервер»определяются четырьмя факторами:
- - какие виды программного обеспечения в логических компонентах;
- - какие механизмы программного обеспечения используются для реализации функций логических компонентов;
- - как логические компоненты распределяются компьютерами в сети;
- - какие механизмы используются для связи компонент между собой.
Исходя из этого, выделяются три подхода, каждый из которых реализован в соответствующей модели технологии «Клиент - сервер»:
- - модель доступа к удаленным данным (Remote Date Access - RDA);
- - модель сервера базы данных (DateBase Server - DBS);
- - модель сервера приложений (Application Server - AS).
Существенным преимуществом RDA-модели является обширный выбор инструментальных средств разработки приложений, которые обеспечивают стремительное образование desktop-приложений, которые работают с SQL-направленными СУБД. Как правило, инструментальные средства поддерживают графический интерфейс пользователя с ОС, а также средства автоматической генерации кода, где смешаны функции представления и прикладные функции.
Несмотря на большое распространение, RDA-модель уступает место наиболее технологичной DBS-модели.
Модель сервера баз данных (DBS) - сетевая архитектура технологии «Клиент - сервер», в основе которой лежит механизм хранимых процедур, который реализует прикладные функции. В DBS - модели понятие информационного ресурса сжато до базы данных из-за того же механизма хранимых процедур, реализованный в СУБД, да и то не во всех.
Положительные стороны DBS-модели перед RDA-моделью очевидны: это и возможность централизованного администрирования различных функций, и снижение трафика сети потому, что вместо SQL-запросов по сети передаются вызовы хранимых процедур, и возможность разделения процедуры между двумя приложениями, и экономия ресурсов компьютера за счет использования однажды созданного плана выполнения процедуры.
Модель сервера приложений (AS) - это сетевая архитектура технологии «Клиент - сервер», которая представляет собой процесс, который выполняется на компьютере-клиенте, и, который отвечает за интерфейс с пользователем (ввод и отображение данных). Важнейшим элементом такой модели является прикладной компонент, который называется сервером приложения, он функционирует на удаленном компьютере (или двух компьютерах). Сервер приложений осуществлен как группа прикладных функций, оформленных в виде сервисов (служб). Каждый сервис предоставляет некоторые услуги всем программам, которые желают и могут ими воспользоваться.
Выучив все модели технологии «Клиент - сервер», можно сделать такой вывод: RDA- и DBS-модели, в основе этих двух моделей лежит двухзвенная схема разделения функций. В RDA-модели прикладные функции переданы клиенту, в DBS-модели их исполнение реализовывается через ядро СУБД. В RDA-модели прикладной компонент сливается с компонентом представления, в DBS-модели интегрируется в компонент доступа к ресурсам.
В AS-модели осуществлена трехзвенная схема разделения функций, где прикладной компонент выделен как главный изолированный элемент приложения, который имеет стандартизированные интерфейсы с двумя прочими компонентами.
Результаты анализа моделей технологий «Файловый сервер» и «Клиент - сервер» представлены в таблице 1.
Несмотря на свое названия технология «Клиент -сервер» также является системой распределенных вычислений. В этом случае распределенные вычисления понимают как архитектура «Клиент - сервер» при участии некоторых серверов. Применительно к распределенной обработке термин «сервер» означает просто программу, отвечающую на запросы и выполняющую необходимые действия по запросу клиента. Поскольку распределенные вычисления - это один из видов систем «Клиент - сервер», то пользователи приобретают такие же преимущества, например, возрастание общей пропускной способности и возможность многозадачной работы. Также, интеграция дискретных сетевых компонентов и обеспечение их работы как единого целого способствует расширению результативности и уменьшению сбережений.
Так как обработка реализовывается в любом месте сети, распределенные вычисления в архитектуре «Клиент-сервер» гарантируют действенное масштабирование. Чтобы добиться баланса между сервером и клиентом, компонент приложения должен осуществляться на сервере только в том случае, если централизованная обработка более результативна. Если логика программы, взаимодействующей с централизованными данными, сосредоточена на той же машине, что и данные, их необязательно передавать по сети, поэтому требования к сетевой среде могут быть снижены.
Вследствие этого можно сделать следующий вывод: если будет нужно работать с малыми информационными системами, которые не требуют графического интерфейса с пользователем, можно использовать FS - модель. Вопрос о графическом интерфейсе можно свободно решить с помощью RDA-модель. DBS-модель это очень хороший вариант для систем управления базами данных(СУБД). AS-модель это лучший вариант для того, чтобы создать большие информационные системы, а также при использовании низкоскоростных каналов связи.
Дальнейшие распределенные вычислительные системы мы будем создавать с использованием технологии клиент-сервер. Эта технология обеспечивает единый подход к обмену информацией между устройствами, будь это компьютеры, расположенные на разных континентах и связанные через интернет или платы Ардуино, лежащие на одном столе и соединенные витой парой.
В дальнейших уроках я планирую рассказывать о создании информационных сетей с использованием:
- контроллеров локальной сети Ethernet;
- WiFi модемов;
- GSM модемов;
- Bluetooth модемов.
Все эти устройства осуществляют обмен данными, используя модель клиент-сервер. По такому же принципу происходит передача информации в сети Интернет.
Я не претендую на полное освещение этой объемной темы. Я хочу дать минимум информации, необходимой для понимания последующих уроков.
Технология клиент-сервер.
Клиент и сервер это программы, расположенное на разных компьютерах, в разных контроллерах и других подобных устройствах. Между собой они взаимодействуют через вычислительную сеть с помощью сетевых протоколов.
Программы-серверы являются поставщиками услуг. Они постоянно ожидают запросы от программ-клиентов и предоставляют им свои услуги (передают данные, решают вычислительные задачи, управляют чем-либо и т.п.). Сервер должен быть постоянно включен и “прослушивать” сеть. Каждая программа-сервер, как правило, может выполнять запросы от нескольких программ-клиентов.
Программа-клиент является инициатором запроса, который может произвести в любой момент. В отличие от сервера клиент не должен быть постоянно включен. Достаточно подключиться в момент запроса.
Итак, в общих чертах система клиент-сервер выглядит так:
- Есть компьютеры, контроллеры Ардуино, планшеты, сотовые телефоны и другие интеллектуальные устройства.
- Все они включены в общую вычислительную сеть. Проводную или беспроводную - не важно. Они могут быть подключены даже к разным сетям, связанным между собой через глобальную сеть, например через интернет.
- На некоторых устройствах установлены программы-серверы. Эти устройства называются серверами, должны быть постоянно включены, и их задача обрабатывать запросы от клиентов.
- На других устройствах работают программы-клиенты. Такие устройства называются клиентами, они инициируют запросы серверам. Их включают только в моменты, когда необходимо обратиться к серверам.
Например, если вы хотите с сотового телефона по WiFi включать утюг, то утюг будет сервером, а телефон – клиентом. Утюг должен быть постоянно включен в розетку, а управляющую программу на телефоне вы будете запускать по необходимости. Если к WiFi сети утюга подключить компьютер, то вы сможете управлять утюгом и с помощью компьютера. Это будет еще один клиент. WiFi микроволновая печь, добавленная в систему, будет сервером. И так систему можно расширять бесконечно.
Передача данных пакетами.
Технология клиент-сервер в общем случае предназначена для использования с объемными информационными сетями. От одного абонента до другого данные могут проходить сложный путь по разным физическим каналам и сетям. Путь доставки данных может меняться в зависимости от состояния отдельных элементов сети. Какие-то компоненты сети могут не работать в этот момент, тогда данные пойдут другим путем. Может изменяться время доставки. Данные могут даже пропасть, не дойти до адресата.
Поэтому простая передача данных в цикле, как мы передавали данные на компьютер в некоторых предыдущих уроках, в сложных сетях совершенно невозможна. Информация передается ограниченными порциями – пакетами. На передающей стороне информация разбивается на пакеты, а на приемной “склеивается” из пакетов в цельные данные. Объем пакетов обычно не больше нескольких килобайт.
Пакет это аналог обычного почтового письма. Он также, кроме информации, должен содержать адрес получателя и адрес отправителя.
Пакет состоит из заголовка и информационной части. Заголовок содержит адреса получателя и отправителя, а также служебную информацию, необходимую для “склейки” пакетов на приемной стороне. Сетевое оборудование использует заголовок для определения, куда передавать пакет.
Адресация пакетов.
На эту тему в интернете есть много подробной информации. Я хочу рассказать как можно ближе к практике.
Уже в следующем уроке для передачи данных с использованием клиент-серверной технологии нам придется задавать информацию для адресации пакетов. Т.е. информацию, куда доставлять пакеты данных. В общем случае нам придется задавать следующие параметры:
- IP-адрес устройства;
- маску подсети;
- доменное имя;
- IP-адрес сетевого шлюза;
- MAC-адрес;
- порт.
Давайте разбираться, что это такое.
IP-адреса.
Технология клиент-сервер предполагает, что все абоненты всех сетей мира подключены к единой глобальной сети. На самом деле во многих случаях это так и есть. Например, большинство компьютеров или мобильных устройств подключено к интернету. Поэтому используется формат адресации, рассчитанный на такое громадное количество абонентов. Но даже если технология клиент-сервер применяется в локальных сетях, все равно сохраняется принятый формат адресов, при явной избыточности.
Каждой точке подключения устройства к сети присваивается уникальный номер – IP-адрес (Internet Protocol Address). IP-адрес присваивается не устройству (компьютеру), а интерфейсу подключения. В принципе устройства могут иметь несколько точек подключения, а значит несколько различных IP-адресов.
IP-адрес это 32х разрядное число или 4 байта. Для наглядности принято записывать его в виде 4 десятичных чисел от 0 до 255, разделенных точками. Например, IP-адрес моего сервера 31.31.196.216.
Для того чтобы сетевому оборудованию было проще выстраивать маршрут доставки пакетов в формат IP-адреса введена логическая адресация. IP-адрес разбит на 2 логических поля: номер сети и номер узла. Размеры этих полей зависят от значения первого (старшего) октета IP-адреса и разбиты на 5 групп – классов. Это так называемый метод классовой маршрутизации.
| Класс | Старший октет | Формат
(С-сеть, |
Начальный адрес | Конечный адрес | Количество сетей | Количество узлов |
| A | 0 | С.У.У.У | 0.0.0.0 | 127.255.255.255 | 128 | 16777216 |
| B | 10 | С.С.У.У | 128.0.0.0 | 191.255.255.255 | 16384 | 65534 |
| C | 110 | С.С.С.У | 192.0.0.0 | 223.255.255.255 | 2097152 | 254 |
| D | 1110 | Групповой адрес | 224.0.0.0 | 239.255.255.255 | - | 2 28 |
| E | 1111 | Резерв | 240.0.0.0 | 255.255.255.255 | - | 2 27 |
Класс A предназначен для применения в больших сетях. Класс B используется в сетях средних размеров. Класс C предназначен для сетей с небольшим числом узлов. Класс D используется для обращения к группам узлов, а адреса класса E зарезервированы.
Существуют ограничения на выбор IP-адресов. Я посчитал главными для нас следующие:
- Адрес 127.0.0.1 называется loopback и используется для тестирования программ в пределах одного устройства. Данные посланы по этому адресу не передаются по сети, а возвращаются программе верхнего уровня, как принятые.
- “Серые” адреса – это IP-адреса разрешенные только для устройств, работающих в локальных сетях без выхода в Интернет. Эти адреса никогда не обрабатываются маршрутизаторами. Их используют в локальных сетях.
- Класс A: 10.0.0.0 – 10.255.255.255
- Класс B: 172.16.0.0 – 172.31.255.255
- Класс C: 192.168.0.0 – 192.168.255.255
- Если поле номера сети содержит все 0, то это означает, что узел принадлежит той же самой сети, что и узел, который отправил пакет.
Маски подсетей.
При классовом методе маршрутизации число битов адресов сети и узла в IP-адресе задается типом класса. А классов всего 5, реально используется 3. Поэтому метод классовой маршрутизации в большинстве случаях не позволяет оптимально выбрать размер сети. Что приводит к неэкономному использованию пространства IP-адресов.
В 1993 году был введен бесклассовый способ маршрутизации, который в данный момент является основным. Он позволяет гибко, а значит и рационально выбирать требуемое количество узлов сети. В этом методе адресации применяются маски подсети переменной длины.
Сетевому узлу присваивается не только IP-адрес, но и маска подсети. Она имеет такой же размер, как и IP-адрес, 32 бит. Маска подсети и определяет, какая часть IP-адреса относится к сети, а какая к узлу.
Каждый бит маски подсети соответствует биту IP-адреса в том же разряде. Единица в бите маски говорит о том, что соответствующий бит IP-адреса принадлежит сетевому адресу, а бит маски со значением 0 определяет принадлежность бита IP-адреса к узлу.
При передаче пакета, узел с помощью маски выделяет из своего IP-адреса сетевую часть, сравнивает ее с адресом назначения, и если они совпадают, то это означает, что передающий и приемный узлы находятся в одной сети. Тогда пакет доставляется локально. В противном случае пакет передается через сетевой интерфейс в другую сеть. Подчеркиваю, что маска подсети не является частью пакета. Она влияет только на логику маршрутизации узла.
По сути, маска позволяет одну большую сеть разбить на несколько подсетей. Размер любой подсети (число IP-адресов) должен быть кратным степени числа 2. Т.е. 4, 8, 16 и т.д. Это условие определяется тем, что биты полей адресов сети и узлов должны идти подряд. Нельзя задать, например, 5 битов - адрес сети, затем 8 битов – адрес узла, а затем опять биты адресации сети.
Пример формы записи сети с четырьмя узлами выглядит так:
Сеть 31.34.196.32, маска 255.255.255.252
Маска подсети всегда состоит из подряд идущих единиц (признаков адреса сети) и подряд идущих нулей (признаков адреса узла). Основываясь на этом принципе, существует другой способ записи той же адресной информации.
Сеть 31.34.196.32/30
/30 это число единиц в маске подсети. В данном примере остается два нуля, что соответствует 2 разрядам адреса узла или четырем узлам.
| Размер сети (количество узлов) | Длинная маска | Короткая маска |
| 4 | 255.255.255.252 | /30 |
| 8 | 255.255.255.248 | /29 |
| 16 | 255.255.255.240 | /28 |
| 32 | 255.255.255.224 | /27 |
| 64 | 255.255.255.192 | /26 |
| 128 | 255.255.255.128 | /25 |
| 256 | 255.255.255.0 | /24 |
- Последнее число первого адреса подсети должно делиться без остатка на размер сети.
- Первый и последний адреса подсети – служебные, их использовать нельзя.
Доменное имя.
Человеку неудобно работать с IP-адресами. Это наборы чисел, а человек привык читать буквы, еще лучше связно написанные буквы, т.е. слова. Для того, чтобы людям было удобнее работать с сетями используется другая система идентификации сетевых устройств.
Любому IP-адресу может быть присвоен буквенный идентификатор, более понятный человеку. Идентификатор называется доменным именем или доменом.
Доменное имя это последовательность из двух или более слов, разделенных точками. Последнее слово это домен первого уровня, предпоследнее – домен второго уровня и т.д. Думаю, об этом знают все.
Связь между IP-адресами и доменными именами происходит через распределенную базу данных, с использованием DNS-серверов. DNS-сервер должен иметь каждый владелец домена второго уровня. DNS-серверы объединены в сложную иерархическую структуру и способны обмениваться между собой данными о соответствии IP-адресов и доменных имен.
Но это все не так важно. Для нас главное, что любой клиент или сервер может обратиться к DNS-серверу с DNS-запросом, т.е. с запросом о соответствии IP-адрес – доменное имя или наоборот доменное имя – IP-адрес. Если DNS-сервер обладает информацией о соответствии IP-адреса и домена, то он отвечает. Если не знает, то ищет информацию на других DNS-серверах и после этого сообщает клиенту.
Сетевые шлюзы.
Сетевой шлюз это аппаратный маршрутизатор или программа для сопряжения сетей с разными протоколами. В общем случае его задача конвертировать протоколы одного типа сети в протоколы другой сети. Как правило, сети имеют разные физические среды передачи данных.
Пример – локальная сеть из компьютеров, подключенная к Интернету. В пределах своей локальной сети (подсети) компьютеры связываются без необходимости в каком-либо промежуточном устройстве. Но как только компьютер должен связаться с другой сетью, например выйти в Интернет, он использует маршрутизатор, который выполняет функции сетевого шлюза.
Роутеры, которые есть у каждого, кто подключен к проводному интернету, являются одним из примеров сетевого шлюза. Сетевой шлюз это точка, через которую обеспечивается выход в Интернет.
В общем случае использование сетевого шлюза выглядит так:
- Допустим у нас система из нескольких плат Ардуино, подключенных через локальную сеть Ethernet к маршрутизатору, который в свою очередь подключен к Интернету.
- В локальной сети мы используем ”серые” IP-адреса (выше об этом написано), которые не допускают выхода в Интернет. У маршрутизатора два интерфейса: нашей локальной сети с “серым” IP-адресом и интерфейс для подключения к Интернету с ”белым” адресом.
- В конфигурации узла мы указываем адрес шлюза, т.е. “белый” IP-адрес интерфейса маршрутизатора, подключенного к Интернету.
- Теперь, если маршрутизатор получает от устройства с ”серым” адресом пакет с запросом на получение информации из Интернета, он заменяет в заголовке пакета ”серый” адрес на свой ”белый” и отправляет его в глобальную сеть. Получив из Интернета ответ, он заменяет ”белый” адрес на запомненный при запросе ”серый” и передает пакет локальному устройству.
MAC-адрес.
MAC-адрес это уникальный идентификатор устройств локальной сети. Как правило, он записывается на заводе-производителе оборудования в постоянную память устройства.
Адрес состоит из 6 байтов. Принято записывать его в шестнадцатеричной системе исчисления в следующих форматах: c4-0b-cb-8b-c3-3a или c4:0b:cb:8b:c3:3a. Первые три байта это уникальный идентификатор организации-производителя. Остальные байты называются ”Номер интерфейса” и их значение является уникальным для каждого конкретного устройства.
IP-адрес является логическим и устанавливается администратором. MAC-адрес – это физический, постоянный адрес. Именно он используется для адресации фреймов, например, в локальных сетях Ethernet. При передаче пакета по определенному IP-адресу компьютер определяет соответствующий MAC-адрес с помощью специальной ARP-таблицы. Если в таблице отсутствуют данные о MAC-адресе, то компьютер запрашивает его с помощью специального протокола. Если MAC-адрес определить не удается, то пакеты этому устройству посылаться не будут.
Порты.
С помощью IP-адреса сетевое оборудование определяет получателя данных. Но на устройстве, например сервере, могут работать несколько приложений. Для того чтобы определить какому приложению предназначены данные в заголовок добавлено еще одно число – номер порта.
Порт используется для определения процесса приемника пакета в пределах одного IP-адреса.
Под номер порта выделено 16 бит, что соответствует числам от 0 до 65535. Первые 1024 портов зарезервированы под стандартные процессы, такие как почта, веб-сайты и т.п. В своих приложениях их лучше не использовать.
Статические и динамические IP-адреса. Протокол DHCP.
IP-адреса могут назначаться вручную. Достаточно утомительная операция для администратора. А в случае, когда пользователь не обладает нужными знаниями, задача становится трудноразрешимой. К тому же не все пользователи находятся постоянно подключенными к сети, а выделенные им статические адреса другие абоненты использовать не могут.
Проблема решается применением динамических IP-адресов. Динамические адреса выдаются клиентам на ограниченное время, пока они непрерывно находятся в сети. Распределение динамических адресов происходит под управлением протокола DHCP.
DHCP – это сетевой протокол, позволяющий устройствам автоматически получать IP-адреса и другие параметры, необходимые для работы в сети.
На этапе конфигурации устройство-клиент обращается к серверу DHCP, и получает от него необходимые параметры. Может быть задан диапазон адресов, распределяемых среди сетевых устройств.
Просмотр параметров сетевых устройств с помощь командной строки.
Существует много способов, как узнать IP-адрес или MAC-адрес своей сетевой карты. Самый простой – это использовать CMD команды операционной системы. Я покажу, как это делать на примере Windows 7.
В папке Windows\System32 находится файл cmd.exe. Это интерпретатор командной строки. С помощь него можно получать системную информацию и конфигурировать систему.
Открываем окно выполнить. Для этого выполняем меню Пуск -> Выполнить или нажимаем комбинацию клавиш Win + R .
Набираем cmd и нажимаем OK или Enter. Появляется окно интерпретатора команд.

Теперь можно задавать любые из многочисленных команд. Пока нас интересуют команды для просмотра конфигурации сетевых устройств.
Прежде всего, это команда ipconfig , которая отображает настройки сетевых плат.

Подробный вариант ipconfig/all .

Только MAC-адреса показывает команда getmac .

Таблицу соответствия IP и MAC адресов (ARP таблицу) показывает команда arp –a .

Проверить связь с сетевым устройством можно командой ping .
- ping доменное имя
- ping IP-адрес
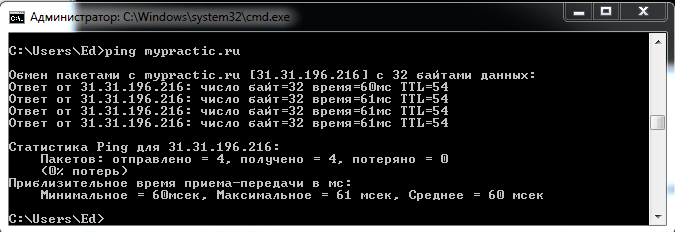
Сервер моего сайта отвечает.
Основные сетевые протоколы.
Я коротко расскажу о протоколах, необходимых нам в дальнейших уроках.
Сетевой протокол это набор соглашений, правил, которые определяют обмен данными в сети. Мы не собираемся реализовывать эти протоколы на низком уровне. Мы намерены использовать готовые аппаратные и программные модули, которые реализуют сетевые протоколы. Поэтому нет необходимости подробно разбирать форматы заголовков, данных и т.п. Но, зачем нужен каждый протокол, чем он отличается от других, когда используется знать надо.
Протокол IP.
Inernet Protocol (межсетевой протокол) доставляет пакеты данных от одного сетевого устройства к другому. IP протокол объединяет локальные сети в единую глобальную сеть, обеспечивая передачу пакетов информации между любыми устройствами сетей. Из представленных в этом уроке протоколов IP находится на самом низком уровне. Все остальные протоколы используют его.
IP протокол работает без установления соединений. Он просто пытается доставить пакет по указанному IP-адресу.
IP обрабатывает каждый пакет данных, как отдельную независимую единицу, не связанную с другими пакетами. Невозможно используя только IP протокол, передать значительный объем связанных данных. Например, в сетях Ethernet максимальный объем данных одного IP-пакета составляет всего 1500 байт.
В протоколе IP нет механизмов, позволяющих контролировать достоверность конечных данных. Контрольные коды используются только для защиты целостности данных заголовка. Т.е. IP не гарантирует, что данные в полученном пакете будут правильными.
Если во время доставки пакета произошла ошибка, и пакет был потерян, то IP не пытается заново послать пакет. Т.е. IP не гарантирует, что пакет будет доставлен.
Коротко о протоколе IP можно сказать, что:
- он доставляет небольшие (не более 1500 байт) отдельные пакеты данных между IP-адресами;
- он не гарантирует, что доставленные данные будут правильными;
Протокол TCP.
Transmission Control Protocol (протокол управления передачей) основной протокол передачи данных Интернета. Он использует способность IP протокола доставлять информацию от одного узла другому. Но в отличии от IP он:
- Позволяет переносить большие объемы информации. Разделение данных на пакеты и “склеивание” данных на приемной стороне обеспечивает TCP.
- Данные передаются с предварительной установкой соединения.
- Производит контроль целостности данных.
- В случае потери данных инициирует повторные запросы потерянных пакетов, устраняет дублирование при получении копий одного пакета.
По сути, протокол TCP снимает все проблемы доставки данных. Если есть возможность, он их доставит. Не случайно это основной протокол передачи данных в сетях. Часто используют терминологию TCP/IP сети.
Протокол UDP.
User Datagram Protokol (протокол пользовательских датаграмм) простой протокол для передачи данных без установления соединения. Данные отправляются в одном направлении без проверки готовности приемника и без подтверждения доставки. Объем данных пакета может достигать 64 кБайт, но на практике многие сети поддерживают размер данных только 1500 байт.
Главное достоинство этого протокола – простата и высокая скорость передачи. Часто применяется в приложениях критичных к скорости доставки данных, таких как видеопотоки. В подобных задачах предпочтительнее потерять несколько пакетов, чем ждать отставшие.
Протоколу UDP свойственно:
- это протокол без установления соединений;
- он доставляет небольшие отдельные пакеты данных между IP-адресами;
- он не гарантирует, что данные вообще будут доставлены;
- он не сообщит отправителю, были ли доставлены данные и не повторит передачу пакета;
- нет упорядоченности пакетов, порядок доставки сообщений не определен.
Протокол HTTP.
Скорее всего, об этом протоколе в следующих уроках буду писать подробнее. А сейчас коротко скажу, что это протокол передачи гипертекста (Hyper Text Transfer Protocol). Он используется для получения информации с веб-сайтов. При этом веб-браузер выступает в роли клиента, а сетевое устройство в качестве веб-сервера.
В следующем уроке будем применять технологию клиент-сервер на практике, используя сеть Ethernet.
Цель лекции: показать, каким образом в веб-технологиях реализуются общие принципы клиент-серверных технологий. Рассмотреть ключевые элементы базового протокола HTTP.
Предметом данного курса являются технологии глобальной сети World Wide Web (сокращенно WWW или просто Web). На русском языке распространенным вариантом является название "Веб".
В частности, в рамках курса будут рассмотрены такие вопросы как: базовые стандарты и протоколы сети Веб, языки разметки и программирования веб-страниц, инструменты разработки и управления веб-контента и приложений для Веб, средства интеграции веб-контента и приложений в Веб.
Сеть Веб представляет собой глобальное информационное пространство, основанное на физической инфраструктуре Интернета и протоколе передачи данных HTTP. Зачастую, говоря об Интернете, подразумевают именно сеть Веб .
Клиент-серверные технологии Веб
Базовым протоколом сети гипертекстовых ресурсов Веб является протокол HTTP. В его основу положено взаимодействие "клиент-сервер ", то есть предполагается, что:
Потребитель-клиент инициировав соединение с поставщиком-сервером посылает ему запрос;
Поставщик-сервер , получив запрос, производит необходимые действия и возвращает обратно клиенту ответ с результатом.
При этом возможны два способа организации работы компьютера-клиента:
Тонкий клиент - это компьютер-клиент, который переносит все задачи по обработке информации на сервер. Примером тонкого клиента может служить компьютер с браузером, использующийся для работы с веб-приложениями.
Толстый клиент , напротив, производит обработку информации независимо от сервера, использует последний в основном лишь для хранения данных.
Прежде чем перейти к конкретным клиент-серверным веб-технологиям, рассмотрим основные принципы и структуру базового протокола HTTP.
Протокол http
HTTP (HyperText Transfer Protocol - RFC 1945, RFC 2616) - протокол прикладного уровня для передачи гипертекста.
Центральным объектом в HTTP является ресурс , на который указывает URI в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя изначально данный протокол предназначен для передачи символьной информации. На первый взгляд это может показаться излишней тратой ресурсов. Действительно, данные в символьном виде занимают больше памяти, сообщения создают дополнительную нагрузку на каналы связи, однако подобный формат имеет много преимуществ. Сообщения, передаваемые по сети, удобочитаемы, и, проанализировав полученные данные, системный администратор может легко найти ошибку и устранить ее. При необходимости роль одного из взаимодействующих приложений может выполнять человек, вручную вводя сообщения в требуемом формате.
В отличие от многих других протоколов, HTTP является протоколом без памяти. Это означает, что протокол не хранит информацию о предыдущих запросах клиентов и ответах сервера. Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами. Например, клиентское веб-приложение, посылающее запросы, может отслеживать задержки ответов, а веб-сервер может хранить IP-адреса и заголовки запросов последних клиентов.
Всё программное обеспечение для работы с протоколом HTTP разделяется на три основные категории:
Серверы - поставщики услуг хранения и обработки информации (обработка запросов).
Клиенты - конечные потребители услуг сервера (отправка запросов).
Прокси-серверы для поддержки работы транспортных служб.
"Классическая" схема HTTP-сеанса выглядит так.
Установление TCP-соединения.
Запрос клиента.
Ответ сервера.
Разрыв TCP-соединения.
Таким образом, клиент посылает серверу запрос, получает от него ответ, после чего взаимодействие прекращается. Обычно запрос клиента представляет собой требование передать HTML-документ или какой-нибудь другой ресурс, а ответ сервера содержит код этого ресурса.
В состав HTTP-запроса, передаваемого клиентом серверу, входят следующие компоненты.
Строка состояния (иногда для ее обозначения используют также термины строка-статус, или строка запроса).
Поля заголовка.
Пустая строка.
Тело запроса.
Строку состояния вместе с полями заголовка иногда называют также заголовком запроса .
Рис. 1.1. Структура запроса клиента.
Строка состояния имеет следующий формат:
метод_запроса URL_pecypca версия_протокола_НТТР
Рассмотрим компоненты строки состояния, при этом особое внимание уделим методам запроса.
Метод , указанный в строке состояния, определяет способ воздействия на ресурс, URL которого задан в той же строке. Метод может принимать значения GET, POST, HEAD, PUT, DELETE и т.д. Несмотря на обилие методов, для веб-программиста по-настоящему важны лишь два из них: GET и POST.
GET. Согласно формальному определению, метод GET предназначается для получения ресурса с указанным URL. Получив запрос GET, сервер должен прочитать указанный ресурс и включить код ресурса в состав ответа клиенту. Ресурс, URL которого передается в составе запроса, не обязательно должен представлять собой HTML-страницу, файл с изображением или другие данные. URL ресурса может указывать на исполняемый код программы, который, при соблюдении определенных условий, должен быть запущен на сервере. В этом случае клиенту возвращается не код программы, а данные, сгенерированные в процессе ее выполнения. Несмотря на то что, по определению, метод GET предназначен для получения информации, он может применяться и в других целях. Метод GET вполне подходит для передачи небольших фрагментов данных на сервер.
POST. Согласно тому же формальному определению, основное назначение метода POST - передача данных на сервер. Однако, подобно методу GET, метод POST может применяться по-разному и нередко используется для получения информации с сервера. Как и в случае с методом GET, URL, заданный в строке состояния, указывает на конкретный ресурс. Метод POST также может использоваться для запуска процесса.
Методы HEAD и PUT являются модификациями методов GET и POST.
Версия протокола HTTP , как правило, задается в следующем формате:
HTTP/версия.модификация
Поля заголовка , следующие за строкой состояния, позволяют уточнять запрос, т.е. передавать серверу дополнительную информацию. Поле заголовка имеет следующий формат:
Имя_поля: Значение
Назначение поля определяется его именем, которое отделяется от значения двоеточием.
Имена некоторых наиболее часто встречающихся в запросе клиента полей заголовка и их назначение приведены в табл. 1.1 .
|
Таблица 1.1. Поля заголовка запроса HTTP. |
|
|
Поля заголовка HTTP-запроса |
Значение |
|
Доменное имя или IP-адрес узла, к которому обращается клиент |
|
|
URL документа, который ссылается на ресурс, указанный в строке состояния |
|
|
Адрес электронной почты пользователя, работающего с клиентом |
|
|
MIME-типы данных, обрабатываемых клиентом. Это поле может иметь несколько значений, отделяемых одно от другого запятыми. Часто поле заголовка Accept используется для того, чтобы сообщить серверу о том, какие типы графических файлов поддерживает клиент |
|
|
Набор двухсимвольных идентификаторов, разделенных запятыми, которые обозначают языки, поддерживаемые клиентом |
|
|
Перечень поддерживаемых наборов символов |
|
|
MIME-тип данных, содержащихся в теле запроса (если запрос не состоит из одного заголовка) |
|
|
Число символов, содержащихся в теле запроса (если запрос не состоит из одного заголовка) |
|
|
Присутствует в том случае, если клиент запрашивает не весь документ, а лишь его часть |
|
|
Используется для управления TCP-соединением. Если в поле содержится Close, это означает, что после обработки запроса сервер должен закрыть соединение. Значение Keep-Alive предлагает не закрывать TCP-соединение, чтобы оно могло быть использовано для последующих запросов |
|
|
Информация о клиенте |
|
Во многих случаях при работе в Веб тело запроса отсутствует. При запуске CGI-сценариев данные, передаваемые для них в запросе, могут размещаться в теле запроса.
Ниже представлен пример HTML-запроса, сгенерированного браузером
GET http://oak.oakland.edu/ HTTP/1.0
Connection: Keep-Alive
User-Agent: Mozilla/4.04 (Win95; I)
Host: oak.oakland.edu
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/png, */*
Accept-Language: en
Accept-Charset: iso-8859-l,*,utf-8
Получив от клиента запрос, сервер должен ответить ему. Знание структуры ответа сервера необходимо разработчику веб-приложений, так как программы, которые выполняются на сервере, должны самостоятельно формировать ответ клиенту.
Подобно запросу клиента, ответ сервера также состоит из четырех перечисленных ниже компонентов.
Строка состояния.
Поля заголовка.
Пустая строка.
Тело ответа.
Ответ сервера клиенту начинается со строки состояния, которая имеет следующий формат:
Версия_протокола Код_ответа Пояснительное_сообщение
Версия_протокола задается в том же формате, что и в запросе клиента, и имеет тот же смысл.
Код_ответа - это трехзначное десятичное число, представляющее в закодированном виде результат обслуживания запроса сервером.
Пояснительное_сообщение дублирует код ответа в символьном виде. Это строка символов, которая не обрабатывается клиентом. Она предназначена для системного администратора или оператора, занимающегося обслуживанием системы, и является расшифровкой кода ответа.
Из трех цифр, составляющих код ответа, первая (старшая) определяет класс ответа, остальные две представляют собой номер ответа внутри класса. Так, например, если запрос был обработан успешно, клиент получает следующее сообщение:
HТТР/1.0 200 ОК
Как видно, за версией протокола HTTP 1.0 следует код 200. В этом коде символ 2 означает успешную обработку запроса клиента, а остальные две цифры (00) - номер данного сообщения.
В используемых в настоящее время реализациях протокола HTTP первая цифра не может быть больше 5 и определяет следующие классы ответов.
1 - специальный класс сообщений, называемых информационными. Код ответа, начинающийся с 1, означает, что сервер продолжает обработку запроса. При обмене данными между HTTP-клиентом и HTTP-сервером сообщения этого класса используются достаточно редко.
2 - успешная обработка запроса клиента.
3 - перенаправление запроса. Чтобы запрос был обслужен, необходимо предпринять дополнительные действия.
4 - ошибка клиента. Как правило, код ответа, начинающийся с цифры 4, возвращается в том случае, если в запросе клиента встретилась синтаксическая ошибка.
5 - ошибка сервера. По тем или иным причинам сервер не в состоянии выполнить запрос.
Примеры кодов ответов, которые клиент может получить от сервера, и поясняющие сообщения приведены в табл. 1.2.
|
Таблица 1.2. Классы кодов ответа сервера. |
||
|
Расшифровка |
Интерпретация |
|
|
Часть запроса принята, и сервер ожидает от клиента продолжения запроса |
||
|
Запрос успешно обработан, и в ответе клиента передаются данные, указанные в запросе |
||
|
В результате обработки запроса был создан новый ресурс |
||
|
Запрос принят сервером, но обработка его не окончена. Данный код ответа не гарантирует, что запрос будет обработан без ошибок. |
||
|
Partial Content |
Сервер возвращает часть ресурса в ответ на запрос, содержавший поле заголовка Range |
|
|
Multiple Choice |
Запрос указывает более чем на один ресурс. В теле ответа могут содержаться указания на то, как правильно идентифицировать запрашиваемый ресурс |
|
|
Moved Permanently |
Затребованный ресурс больше не располагается на сервере |
|
|
Moved Temporarily |
Затребованный ресурс временно изменил свой адрес |
|
|
В запросе клиента обнаружена синтаксическая ошибка |
||
|
Имеющийся на сервере ресурс недоступен для данного пользователя |
||
|
Ресурс, указанный клиентом, на сервере отсутствует |
||
|
Method Not Allowed |
Сервер не поддерживает метод, указанный в запросе |
|
|
Internal Server Error |
Один из компонентов сервера работает некорректно |
|
|
Not Implemented |
Функциональных возможностей сервера недостаточно, чтобы выполнить запрос клиента |
|
|
Service Unavailable |
Служба временно недоступна |
|
|
HTTP Version not Supported |
Версия HTTP, указанная в запросе, не поддерживается сервером |
|
В ответе используется такая же структура полей заголовка, как и в запросе клиента. Поля заголовка предназначены для того, чтобы уточнить ответ сервера клиенту. Описание некоторых из полей, которые можно встретить в заголовке ответа сервера, приведено в табл. 1.3.
|
Таблица 1.3. Поля заголовка ответа веб-сервера. |
|
|
Имя поля |
Описание содержимого |
|
Имя и номер версии сервера |
|
|
Время в секундах, прошедшее с момента создания ресурса |
|
|
Список методов, допустимых для данного ресурса |
|
|
Content-Language |
Языки, которые должен поддерживать клиент для того, чтобы корректно отобразить передаваемый ресурс |
|
MIME -тип данных, содержащихся в теле ответа сервера |
|
|
Число символов, содержащихся в теле ответа сервера |
|
|
Дата и время последнего изменения ресурса |
|
|
Дата и время, определяющие момент генерации ответа |
|
|
Дата и время, определяющие момент, после которого информация, переданная клиенту, считается устаревшей |
|
|
В этом поле указывается реальное расположение ресурса. Оно используется для перенаправления запроса |
|
|
Директивы управления кэшированием. Например, no-cache означает, что данные не должны кэшироваться |
|
В теле ответа содержится код ресурса, передаваемого клиенту в ответ на запрос. Это не обязательно должен быть HTML-текст веб-страницы. В составе ответа могут передаваться изображение, аудио-файл, фрагмент видеоинформации, а также любой другой тип данных, поддерживаемых клиентом. О том, как следует обрабатывать полученный ресурс, клиенту сообщает содержимое поля заголовка Content-type.
Ниже представлен пример ответа сервера на запрос, приведенный в предыдущем разделе. В теле ответа содержится исходный текст HTML-документа.
Server: Microsoft-IIS/5.1
X-Powered-By: ASP.NET
Content-Type: text/html
Accept-Ranges: bytes
ETag: "b66a667f948c92:8a5"
Content-Length: 426