Как построить экспоненциальный график в excel. Построение линейного тренда
Тренд - это закономерность описывающая подъем или падение показателя в динамике. Если изобразить любой динамический ряд (статистические данные, представляющие собой список зафиксированных значений изменяемого показателя во времени) на графике, часто выделяется определенный угол – кривая либо постепенно идет на увеличение или на уменьшение, в таких случаях принято говорить, что ряд динамики имеет тенденцию (к росту или падению соответственно).
Тренд как модель
Если же построить модель, описывающую это явление, то получается довольно простой и очень удобный инструмент для прогнозирования не требующий каких-либо сложных вычислений или временных затрат на проверку значимости или адекватности влияющих факторов.
Итак, что же собой представляет тренд как модель? Это совокупность расчетных коэффициентов уравнения, которые выражают регрессионную зависимость показателя (Y) от изменения времени (t). То есть, это точно такая же регрессия, как и те, что мы рассматривали ранее, только влияющим фактором здесь выступает именно показатель времени.
Важно!
В расчетах под t обычно подразумевается не год, номер месяца или недели, а именно порядковый номер периода в изучаемой статистической совокупности – динамическом ряде. К примеру, если динамический ряд изучается за несколько лет, а данные фиксировались ежемесячно, то использовать обнуляющуюся нумерацию месяцев, с 1 по 12 и опять сначала, в корне неверно. Также неверно в случае, если изучение ряда начинается, к примеру, с марта месяца в качестве значения t использовать 3 (третий месяц в году), если это первое значение в изучаемой совокупности, то его порядковый номер должен быть 1.
Модель линейного тренда
Как и любая другая регрессия, тренд может быть как линейным (степень влияющего фактора t равна 1) так и нелинейным (степень больше или меньше единицы). Так как линейная регрессия является самой простейшей, хотя далеко не всегда самой точной, то рассмотрим более детально именно этот тип тренда.
Общий вид уравнения линейного тренда:
Y(t) = a 0 + a 1 *t + Ɛ
Где a 0 – это нулевой коэффициент регрессии, то есть, то каким будет Y в случае, если влияющий фактор будет равен нулю, a 1 – коэффициент регрессии, который выражает степень зависимости исследуемого показателя Y от влияющего фактора t, Ɛ – случайная компонента или стандартная ошибка, по сути являет собой разницу между реально существующими значениями Y и расчетными. t – это единственный влияющий фактор – время.
Чем более выраженная тенденция роста показателя или его падения, тем будет больше коэффициент a 1 . Соответственно, предполагается, что константа a 0 совместно со случайной компонентой Ɛ отражают остальные регрессионные влияния, помимо времени, то есть всех прочих возможных влияющих факторов.
Рассчитать коэффициенты модели можно стандартным Методом наименьших квадратов (МНК). Со всеми этими расчетами Microsoft Excel справляется на ура самостоятельно, при чем, чтобы получить модель линейного тренда либо готовый прогноз существует целых пять способов, которые мы по отдельности разберем ниже.
Графический способ получения линейного тренда
В этом и во всех дальнейших примерах будем использовать один и тот же динамический ряд – уровень ВВП, который вычисляется и фиксируется ежегодно, в нашем случае исследование будет проходить на периоде с 2004-го по 2012-й гг.

Добавим к исходным данным еще один столбец, который назовем t и пометим цифрами по возрастающей порядковые номера всех зафиксированных значений ВВП за указанный период с 2004-го по 2012-й гг. – 9 лет или 9 периодов .

Эксель добавит пустое поле – разметку под будущий график, выделяем этот график и активируем появившуюся вкладку в панели меню – Конструктор , ищем кнопку Выбрать данные , в отрывшемся окне жмем кнопочку Добавить . Всплывшее окошко предложит выбрать данные для построения диаграммы. В качестве значения поля Имя ряда выбираем ячейку, которая содержит текст, наиболее полно отвечающий названию графика. В поле Значения X указываем интервал ячеек стобца t – влияющего фактора. В поле Значения Y указываем интервал ячеек столбца с известными значениями ВВП (Y) – исследуемого показателя.

Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда

Откроется окошко для настройки параметров построения линии тренда, где среди типов моделей выбираем Линейная , ставим галочки напротив пунктов Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации R2 , этого будет достаточно чтобы на графике отобразилась уже построенная линия тренда, а также математический вариант отображения модели в виде готового уравнения и показатель качества модели R 2 . Если вас интересует отображение на графике прогноза, чтобы визуально оценить отрыв исследуемого показателя укажите в поле Прогноз вперед на количество интересующих периодов.

Собственно это все, что касается этого способа, можно конечно добавить, что отображаемое уравнение линейного тренда это и есть непосредственно сама модель, которую можно использовать, в качестве формулы, чтобы получить расчетные значения по модели и соответственно точные значения прогноза (прогноз отображаемый на графике, оценить можно лишь приблизительно), что мы и сделали в приложенному к статье примере.
Построение линейного тренда с помощью формулы ЛИНЕЙН

Суть этого метода сводится к поиску коэффициентов линейного тренда с помощью функции ЛИНЕЙН , затем, подставляя эти влияющие коэффициенты в уравнение, получим прогнозную модель.
Нам потребуется выделить две рядом стоящие ячейки (на скриншоте это ячейки A38 и B38), далее в строке формул вверху (выделено красным на скриншоте выше) вызываем функцию, написав «=ЛИНЕЙН(», после чего эксель выведет подсказки того, что требуется для этой функции, а именно:
- выделяем диапазон с известными значениями описываемого показателя Y (в нашем случае ВВП, на скриншоте диапазон выделен синим) и ставим точку с запятой
- указываем диапазон влияющих факторов X (в нашем случае это показатель t, порядковый номер периодов, на скриншоте выделено зеленым) и ставим точку с запятой
- следующий по порядку требуемый параметр для функции – это определение того нужно ли рассчитывать константу, так как мы изначально рассматриваем модель с константой (коэффициент a 0 ), то ставим либо «ИСТИНА» либо «1» и точку с запятой
- далее нужно указать требуется ли расчет параметров статистики (в случае, если бы мы рассматривали этот вариант, то изначально пришлось бы выделить диапазон «под формулу» на несколько строк ниже). Указывать необходимость расчета параметров статистики, а именно стандартного значение ошибки для коэффициентов, коэффициента детерминированности, стандартной ошибки для Y, критерия Фишера, степеней свободы и пр. , есть смысл только тогда, когда вы понимаете, что они означают, в этом случае ставим либо «ИСТИНА», либо «1». В случае упрощенного моделирования, которому мы пытаемся научиться, на этом этапе прописывания формулы, ставим «ЛОЖЬ» либо «0» и добавляем после закрывающую скобочку «)»
- чтобы «оживить» формулу, то есть заставить ее работать после прописывания всех необходимых параметров, не достаточно нажать кнопку Enter, необходимо последовательно зажать три клавиши: Ctrl, Shift, Enter

Как видим на скриншоте выше, выделенные нами под формулу ячейки заполнились расчетными значениями коэффициентов регрессии для линейного тренда, в ячейке B38 находится коэффициент a 0 , а в ячейке A38 - коэффициент зависимости от параметра t (или x ), то есть a 1 . Подставляем полученные значения в уравнение линейной функции и получаем готовую модель в математическом выражении – y = 169 572,2+138 454,3*t
Чтобы получить расчетные значения Y по модели и, соответственно, чтобы получить прогноз, нужно просто подставить формулу в ячейку экселя, а вместо t указать ссылку на ячейку с требуемым номером периода (смотрите на скриншоте ячейку D25 ).
Для сравнения полученной модели с реальными данными, можно построить два графика, где в качестве Х указать порядковый номер периода, а в качестве Y в одном случае – реальный ВВП, а, в другом – расчетный (на скриншоте диаграмма справа).
Построение линейного тренда с помощью инструмента Регрессия в Пакете анализа
В статье , по сути, полностью описан этот метод, единственная же разница в том, что в наших исходных данных только один влияющий фактор Х (номер периода – t ).

Как видно на рисунке выше, диапазон данных с известными значениями ВВП выделен как входной интервал Y , а соответствующий ему диапазон с номерами периодов t – как входной интервал Х . Итоги расчетов Пакетом анализа выносятся на отдельный лист и выглядит как набор таблиц (см. рисунок ниже) на котором нас интересуют ячейки, которые были закрашены мною в желтый и зеленый цвета. По аналогии с порядком, расписанным в указанной выше статье, из полученных коэффициентов собирается модель линейного тренда y=169 572,2+138 454,3*t , на основе которой и делаются прогнозы.

Прогнозирование с помощью линейного тренда через функцию ТЕНДЕНЦИЯ
Этот метод отличается от предыдущих тем, что он пропускает необходимые ранее этапы расчета параметров модели и подстановки полученных коэффициентов вручную в качестве формулы в ячейку, чтобы получить прогноз, эта функция как раз и выдает уже готовое рассчитанное прогнозное значение на основе известных исходных данных.

В целевую ячейку (ту ячейку, где хотим видеть результат) ставим знак равно и вызываем волшебную функцию, прописав «ТЕНДЕНЦИЯ(», далее необходимо выделить , то есть , после ставим точку с запятой и выделяем диапазон с известными значениями Х, то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП, опять ставим точку с запятой и выделяем ячейку с номером периода, для которого мы делаем прогноз (правда, в нашем случае, номер периода можно указать не ссылкой на ячейку, а просто цифрой прямо в формуле), далее ставим еще одну точку с запятой и указываем ИСТИНА или 1 , в качестве подтверждения для расчета коэффициента a 0 , наконец, ставим закрывающую скобочку и нажимаем клавишу Enter .
Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.
Прогнозирование с помощью линейного тренда через функцию ПРЕДСКАЗ
Суть данной функции целиком и полностью идентична предыдущей, разница лишь в порядке прописывания исходных данных в формуле и в том, что нет настройки для наличия или отсутствия коэффициента a 0 (то есть функция подразумевает, что этот коэффициент, в любом случае, есть)

Как видно с рисунка выше, в целевую ячейку прописываем «=ПРЕДСКАЗ(» и затем указываем ячейку с номером периода , для которого необходимо просчитать значение по линейному тренду, то есть прогноз, после ставим точку с запятой, далее выделяем диапазон известных значений Y , то есть столбец с известными значениями ВВП , после ставим точку с запятой и выделяем диапазон с известными значениями Х , то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП и, наконец, ставим закрывающую скобочку и жмем клавишу Enter .
Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении.
Подводя итог к статье
Можно сказать, что каждый из методов может быть наиболее приемлемым среди прочих в зависимости от текущей цели, которую мы ставим перед собой. Первые три метода пересекаются между собой как по смыслу, так и по результату, и годятся для любой более или менее серьезной работы, где необходимо описание модели и ее качества. В свою очередь, последние два метода также идентичны между собой и максимально быстро вам дадут ответ, например, на вопрос: «Какой прогноз продаж на следующий год?».
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y(t) = a0 + a1*t + E
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Построение модели
Итак, мы знаем объем продаж за прошедшие 9 месяцев. Вот, что из себя представляет наша табличка:
Следующее, что мы должны сделать — это определить коэффициенты a0 и a1 для прогнозирования объема продаж за 10-ый месяц.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
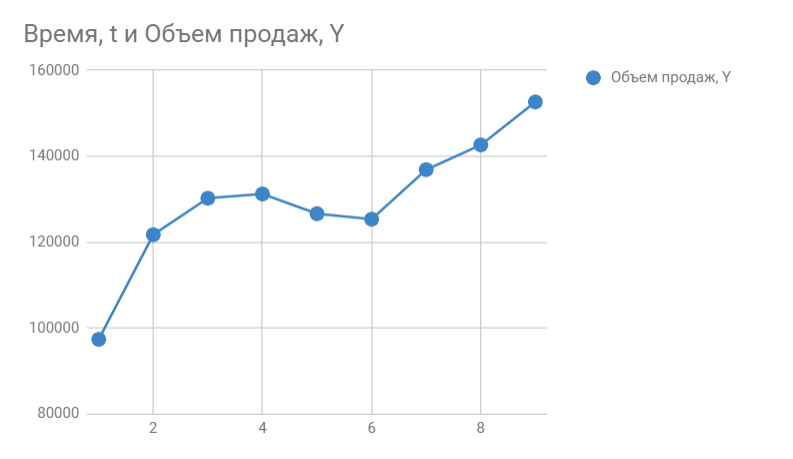
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда . В настройках выбираем Ярлык — Уравнение и Показать R^2 .
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:

На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Прогнозируем
y = 4856*10 + 105104
Получаем 153664 продажи в следующем месяце. Если добавим новую точку на график, то сразу видим, что R^2 улучшился.

Таким образом вы можете спрогнозировать данные на несколько месяцев вперед, но без учета других факторов ваш прогноз будет лежать на линии тренда и будет не таким информативным как хотелось бы. К тому же, долгосрочный прогноз, сделанный таким способом будет очень приблизительным.
Повысить точность модели можно добавлением сезонности к функции тренда, что мы и сделаем в следующей статье.
Диаграммы и графики используются для анализа числовых данных, например, для оценки зависимости меж-ду двумя видами значений. С этой целью к данным диаграммы или графика можно добавить линию тренда и ее уравнение, прогнозные значения, рассчитанные на несколько периодов вперед или назад.
Линия тренда представляет собой прямую или кривую линию, аппроксимирующую (приближающую) исходные данные на основе уравнения регрессии или скользящего среднего. Аппроксимация определяется по ме-тоду наименьших квадратов. В зависимости от характера поведения исходных данных (убыва-ют, возрастают и т.д.) выбирается метод интерполяции, который сле-дует использовать для построения тренда.
Предусмотрено несколько вариантов формирования линии трен-да.
Линейной функцией: y=mx+b
где m — тангенс угла наклона прямой, b — смещение.
Прямая линия тренда (линейный тренд) наилучшим образом подходит для величин, изменяющихся с постоянной скоростью. Приме-няется в случаях, когда точки данных расположены близко к прямой.
Логарифмической функцией: y=c*lnx+b
где с и b — константы.
Логарифмическая линия тренда соответствует ряду данных, значения которого вначале быстро растут или убывают, а затем постепенно стабилизируются. Может использоваться для положительных и отрицательных данных.
Полиномиальной функцией (до 6-й степени включительно): y= b + c 1 *x + c 2 *x 2 + c 3 *x 3 + ...+ c 6* x 6
где b, c 1 , c 2 , ... c 6 — константы.
Полиномиальная линия тренда используется для описания попеременно возрастающих и убывающих данных. Степень полинома подбирают таким образом, чтобы она была на единицу больше количества экстремумов (максимумов и минимумов) кривой.
Степенной функцией: y = cxb
где c и b — константы.
Степенная линия тренда дает хорошие результаты для положительных данных с постоянным ускорением. Для рядов с нулевыми или отрицательными значениями построение указанной линии трен-да невозможно.
Экспоненциальной функцией: y = cebx
где c и b — константы, е — основание натурального логарифма.
Экспоненциальный тренд используется в случае непрерывного возрастания изменения данных. Построение указанного тренда не- возможно, если в множестве значений членов ряда присутствуют нулевые или отрицательные данные.
С использованием линейной фильтрации по формуле: F t = (A t +A (t-1) +⋯+A (t-n+1))/n
где n — общее число членов ряда, t — заданное число точек (2 ≤ t < n).
Тренд с линейной фильтрацией позволяет сгладить колебания данных, наглядно демонстрируя характер зависимостей. Для построения указанной линии тренда пользователь должен задать число — параметр фильтра. Если задано число 2, то первая точка линии трен-да определяется как среднее значение из первых двух элементов данных, вторая точка — как среднее второго и третьего элементов данных и т.д.
Для некоторых типов диаграмм линия тренда в принципе не мо-жет быть построена — диаграмм с накоплением, объемных, лепест-ковых, круговых, поверхностных, кольцевых. При возможности к диаграмме можно добавить несколько линий с разными па-раметрами. Соответствие линии тренда фактическим значениям ряда данных устанавливается с помощью коэффициента достоверности аппрок-симации:
Линия тренда, а также ее параметры добавляются к данным диа-граммы следующими командами:

При необходимости параметры линии можно изменить, вызвав щелчком мыши по ряду данных диаграммы или линии трен-да окно Формат линии тренда. Можно добавить (или удалить) урав-нение регрессии, коэффициент достоверности аппроксимации, оп-ределить направление и прогноз изменения ряда данных, а также выполнить коррекцию оформительских элементов линии тренда. Выделенная линия тренда может быть также удалена.
На рисунке приведена таблица данных по изменению стоимости ценной бумаги. На основе этих условных данных построена точечная диаграмма, добавлена поли-номиальная линия тренда третьего порядка (задана штриховой ли-нией) и некоторые другие параметры. Полученное значение коэф-фициента достоверности аппроксимации R 2 на диаграмме близко к единице, что свидетельствует о близости расчетной линии тренда с данными задачи. Прогнозное значение изменения стоимости ценной бумаги направлено в сторону роста.
Построение графиков
Регрессионный анализ
Уравнением регрессии Y от X называют функциональную зависимость у=f(x) , а ее график – линией регрессии.
Excel позволяет создавать диаграммы и графики довольно приемлемого качества. Excel имеется специальное средство - Мастер диаграмм, под руководством которого пользователь проходит все четыре этапа процесса построения диаграммы или графика.
Как правило, построение графика начинают с выделения диапазона, содержащего данные, по которым он должен быть построен. Такое начало упрощает дальнейший ход построения графика. Однако диапазон с исходными данными можно делить и на втором этапе диалога с МАСТЕРОМ ДИАГРАММ . В Еxcel 2003 МАСТЕР ДИАГРАММ находится в меню в виде кнопки или диаграмму можно создать путем нажатия на вкладку ВСТАВКА и в открывшемся списке найти пункт ДИАГРАММА. В Excel 2007 также находим вкладку ВСТАВКА (рис. 31).

Рис. 31. МАСТЕР ДИАГРАММ в Excel 2007
Наиболее просто выделить диапазон исходных данных, в котором эти данные находятся в смежных рядах (столбцах или строках), - надо щелкнуть по левой верхней ячейке диапазона и затем протащить указатель мыши до правой нижней ячейки диапазона. При выделении данных, находящихся в несмежных рядах, указатель мыши перетаскивают по выделяемым рядам при нажатой клавише Ctrl. Если один из рядов данных имеет ячейку с названием, остальные выделенные ряды также должны иметь соответствующую ячейку, даже если она пустая.
Для проведения регрессионного анализа лучше всего использовать диаграмму типа Точечная (рис. 30). При ее построении Excel воспринимает первый ряд выделенного диапазона исходных данных как набор значений аргумента функций, графики которых нужно построить (один и тот же набор для всех функций). Следующие ряды воспринимаются как наборы значений самих функций (каждый ряд содержит значения одной из функций, соответствующие заданным значениям аргумента, находящимся в первом ряду выделенного диапазона).
В Excel 2007 названия осей ставятся во вкладке меню МАКЕТ (рис. 32).
Рис. 32. Настойка названий осей графика в Excel 2007
Для получения математической модели необходимо построить на графике линию тренда. В Excel 2003 и 2007 нужно щелкнуть правой кнопкой мыши на точки графика. Тогда в Excel 2003 появится вкладка с перечнем пунктов, из которых выбираем ДОБАВИТЬ ЛИНИЮ ТРЕНДА (рис. 33).

Рис. 33. ДОБАВИТЬ ЛИНИЮ ТРЕНДА
После нажатия на пункт ДОБАВИТЬ ЛИНИЮ ТРЕНДА появится окно ЛИНИЯ ТРЕНДА (рис. 34). Во вкладке ТИП можно выбрать следующие типы линий: линейная, логарифмическая, экспоненциальная, степенная, полиномиальная, линейная фильтрация.

Рис. 34. Окно ЛИНИЯ ТРЕНДА в Excel 2003
Во вкладке ПАРАМЕТРЫ (рис. 35)устанавливаем флажок напротив пунктов ПОКАЗЫВАТЬ УРАВНЕНИЕ НА ДИАГРАММЕ, тогда на графике появится математическая модель данной зависимости. Также флажок ставим напротив пункта ПОКАЗЫВАТЬ НА ДИАГРАММЕ ВЕЛИЧИНУ ДОСТОВЕРНОСТИ АППРОКСИМАЦИИ (R^2). Чем ближе величина достоверности аппроксимации к 1, тем ближе подходит выбранная кривая к точкам на графике. Далее нажимаем на кнопку ОК . На графике появится линия тренда, соответствующее ей уравнение и величина достоверности аппроксимации.

Рис. 35. Вкладка ПАРАМЕТРЫ
В Excel 2007 после того, как щелкнем правой кнопкой мыши на точки графика, появится список пунктов меню, из которого ВЫБИРАЕМ ДОБАВИТЬ ЛИНИЮ ТРЕНДА (рис. 36).

Рис. 36. ДОБАВИТЬ ЛИНИЮ ТРЕНДА

Рис. 37. Вкладка ПАРАМЕТРЫ ЛИНИИ ТРЕНДА
Устанавливаем необходимые флажки и нажимаем кнопку ЗАКРЫТЬ .
На графике появится линия тренда, соответствующее ей уравнение и величина достоверности аппроксимации.
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
St =aYt +(1−α)St−1,
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.



