Множественный регрессионный анализ в excel. Регрессия и excel
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.

Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
Это наиболее распространенный способ показать зависимость какой-то переменной от других, например, как зависит уровень ВВП от величины иностранных инвестиций или от кредитной ставки Нацбанка или от цен на ключевые энергоресурсы .
Моделирование позволяет показать величину этой зависимости (коефициенты), благодаря которым можно делать непосредственно прогноз и осуществлять какое-то планирование, опираясь на эти прогнозы. Также, опираясь на регрессионный анализ, можно принимать управленческие решения направленные на стимулирование приоритетных причин влияющих на конечный результат, собственно модель и поможет выделить эти приоритетные факторы.
Общий вид модели линейной регрессии:
Y=a 0 +a 1 x 1 +...+a k x k
где a - параметры (коэффициенты) регрессии, x - влияющие факторы, k - количество факторов модели.
Исходные данные
Среди исходных данных нам необходим некий набор данных, который бы представлял из себя несколько последовательных или связанных между собой величин итогового параметра Y (например, ВВП) и такое же количество величин показателей, влияние которых мы изучаем (например, иностранные инвестиции).
На рисунке выше показана таблица с этими самыми исходными данными, в качестве Y выступает показатель экономически активного населения, а количество предприятий, размер инвестиций в капитал и доходов населения - это влияющие факторы, то бишь иксы.
По рисунку также можно сделать ошибочный вывод, что речь в моделировании может идти только о динамических рядах, то есть моментным рядам зафиксированных последовательно во времени, но это не так, с тем же успехом можно моделировать и в разрезе структуры, например, величины указанные в таблице могут быть разбиты не годам, а по областям.
Для построения адекватных линейных моделей желательно чтобы исходные данные не имели сильных перепадов или обвалов, в таких случаях желательно проводить сглаживание, но о сглаживании поговорим в следующий раз.
Пакет анализа
Параметры модели линейной регрессии можно рассчитать и вручную с помощью Метода наименьших квадратов (МНК), но это довольно затратно по времени. Немного быстрее это можно посчитать по этому же методу с помощью применения формул в Excel, где сами вычисления будет делать программа, но проставлять формулы все равно придется вручную.
В Excel есть надстройка Пакет анализа , который является довольно мощным инструментом в помощь аналитику. Этот инструментарий, помимо всего прочего, умеет рассчитывать параметры регрессии, по тому же МНК, всего в несколько кликов, собственно, о том как этим инструментом пользоваться дальше и пойдет речь.
Активируем Пакет анализа
По умолчанию эта надстройка отключена и в меню вкладок вы ее не найдете, поэтому пошагово рассмотрим как ее активировать.

В эксель, слева вверху, активируем вкладку Файл , в открывшемся меню ищем пункт Параметры и кликаем на него.

В открывшемся окне, слева, ищем пункт Надстройки и активируем его, в этой вкладке внизу будет выпадающий список управления, где по умолчанию будет написано Надстройки Excel , справа от выпадающего списка будет кнопка Перейти , на нее и нужно нажать.

Всплывающее окошко предложит выбрать доступные надстройки, в нем необходимо поставить галочку напротив Пакет анализа и заодно, на всякий случай, Поиск решения (тоже полезная штука), а затем подтвердить выбор кликнув по кнопочке ОК .
Инструкция по поиску параметров линейной регрессии с помощью Пакета анализа
После активации надстройки Пакета анализа она будет всегда доступна во вкладке главного меню Данные под ссылкой Анализ данных
В активном окошке инструмента Анализа данных из списка возможностей ищем и выбираем Регрессия

Далее откроется окошко для настройки и выбора исходных данных для вычисления параметров регрессионной модели. Здесь нужно указать интервалы исходных данных, а именно описываемого параметра (Y) и влияющих на него факторов (Х), как это на рисунке ниже, остальные параметры, в принципе, необязательны к настройке.

После того как выбрали исходные данные и нажали кнопочку ОК, Excel выдает расчеты на новом листе активной книги (если в настройках не было выставлено иначе), эти расчеты имеют следующий вид:

Ключевые ячейки залил желтым цветом именно на них нужно обращать внимание в первую очередь, остальные параметры значимость также немаловажны, но их детальный разбор требует пожалуй отдельного поста.
Итак, 0,865 - это R 2 - коэффициент детерминации, показывающий что на 86,5% расчетные параметры модели, то есть сама модель, объясняют зависимость и изменения изучаемого параметра - Y от исследуемых факторов - иксов . Если утрировано, то это показатель качества модели и чем он выше тем лучше. Понятное дело, что он не может быть больше 1 и считается неплохо, когда R 2 выше 0,8, а если меньше 0,5, то резонность такой модели можно смело ставить под большой вопрос.
Теперь перейдем к коэффициентам модели
:
2079,85
- это a 0
- коэффициент который показывает какой будет Y в случае, если все используемые в модели факторы будут равны 0, подразумевается что это зависимость от других неописанных в модели факторов;
-0,0056
- a 1
- коэффициент, который показывает весомость влияния фактора x 1 на Y, то есть количество предприятий в пределах данной модели влияет на показатель экономически активного населения с весом всего -0,0056 (довольно маленькая степень влияния). Знак минус показывает что это влияние отрицательно, то есть чем больше предприятий, тем меньше экономически активного населения, как бы это ни было парадоксальным по смыслу;
-0,0026
- a 2
- коэффициент влияния объема инвестиций в капитал на величину экономически активного населения, согласно модели, это влияние также отрицательно;
0,0028
- a 3
- коэффициент влияния доходов населения на величину экономически активного населения, здесь влияние позитивное, то есть согласно модели увеличение доходов будет способствовать увеличению величины экономически активного населения.
Соберем рассчитанные коэффициенты в модель:
Y = 2079,85 - 0,0056x 1 - 0,0026x 2 + 0,0028x 3
Собственно, это и есть линейная регрессионная модель, которая для исходных данных, используемых в примере, выглядит именно так.
Расчетные значения модели и прогноз
Как мы уже обсуждали выше, модель строится не только чтобы показать величину зависимостей изучаемого параметра от влияющих факторов, но и чтобы зная эти влияющие факторы можно было делать прогноз. Сделать этот прогноз довольно просто, нужно просто подставить значения влияющих факторов в место соответствующих иксов в полученное уравнение модели. На рисунке ниже эти расчеты сделаны в экселе в отдельном столбце.

Фактические значения (те что имели место в реальности) и расчетные значения по модели на этом же рисунке отображены в виде графиков, чтобы показать разность, а значит погрешность модели.
Повторюсь еще раз, для того чтобы сделать прогноз по модели нужно чтобы были известные влияющие факторы, а если речь идет о временном ряде и соответственно прогнозе на будущее, например, на следующий год или месяц, то далеко не всегда можно узнать какие будут влияющие факторы в этом самом будущем. В таких случаях, нужно еще делать прогноз и для влияющих факторов, чаще всего это делают с помощью авторегрессионной модели - модели, в которой влияющими факторами являются сам исследуемый объект и время, то есть моделируется зависимость показателя от того каким он был в прошлом.
Как строить авторегрессионную модель рассмотрим в следующей статье, а сейчас предположим, что, то какие будут величины влияющих факторов в будущем периоде (в примере 2008 год) нам известно, подставляя эти значения в расчеты мы получим наш прогноз на 2008 год.
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением

На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:
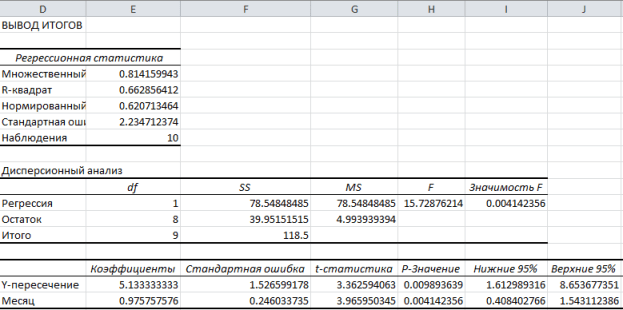
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
В Excel имеется еще более быстрый и удобный способ построить график линейной регрессии (и даже основных видов нелинейных регрессий, о чем см. далее). Это можно сделать следующим образом:
1) выделить столбцы с данными X и Y (они должны располагаться именно в таком порядке!);
2) вызвать Мастер диаграмм и выбрать в группе Тип – Точечная и сразу нажать Готово ;
3) не сбрасывая выделения с диаграммы, выбрать появившейся пункт основного меню Диаграмма , в котором следует выбрать пункт Добавить линию тренда ;
4) в появившемся диалоговом окне Линия тренда во вкладке Тип выбрать Линейная ;
5) во вкладке Параметры можно активизировать переключатель Показывать уравнение на диаграмме , что позволит увидеть уравнение линейной регрессии (4.4), в котором будут вычислены коэффициенты (4.5).
6) В этой же вкладке можно активизировать переключатель Поместить на диаграмму величину достоверности аппроксимации (R^2) . Эта величина есть квадрат коэффициента корреляции (4.3) и она показывает, насколько хорошо рассчитанное уравнение описывает экспериментальную зависимость. Если R 2 близок к единице, то теоретическое уравнение регрессии хорошо описывает экспериментальную зависимость (теория хорошо согласуется с экспериментом), а если R 2 близок к нулю, то данное уравнение не пригодно для описания экспериментальной зависимости (теория не согласуется с экспериментом).
В результате выполнения описанных действий получится диаграмма с графиком регрессии и ее уравнением.
§4.3. Основные виды нелинейной регрессии
Параболическая и полиномиальная регрессии.
Параболической зависимостью величины Y от величины Х называется зависимость, выраженная квадратичной функцией (параболой 2-ого порядка):
Это уравнение называется уравнением параболической регрессии Y на Х . Параметры а , b , с называются коэффициентами параболической регрессии . Вычисление коэффициентов параболической регрессии всегда громоздко, поэтому для расчетов рекомендуется использовать компьютер.
Уравнение (4.8) параболической регрессии является частным случаем более общей регрессии, называемой полиномиальной. Полиномиальной зависимостью величины Y от величины Х называется зависимость, выраженная полиномом n -ого порядка:
где числа а i (i =0,1,…, n ) называются коэффициентами полиномиальной регрессии .
Степенная регрессия.
Степенной зависимостью величины Y от величины Х называется зависимость вида:
Это уравнение называется уравнением степенной регрессии Y на Х . Параметры а и b называются коэффициентами степенной регрессии .
ln =lna +b· lnx . (4.11)
Это уравнение описывает прямую на плоскости с логарифмическими координатными осями lnx и ln . Поэтому критерием применимости степенной регрессии служит требование того, чтобы точки логарифмов эмпирических данных lnx i и lnу i находились ближе всего к прямой (4.11).
Показательная регрессия.
Показательной (или экспоненциальной ) зависимостью величины Y от величины Х называется зависимость вида:
(или ). (4.12)
Это уравнение называется уравнением показательной (или экспоненциальной ) регрессии Y на Х . Параметры а (или k ) и b называются коэффициентами показательной (или экспоненциальной ) регрессии .
Если прологарифмировать обе части уравнения степенной регрессии, то получится уравнение
ln =x· lna +lnb (или ln =k·x +lnb ). (4.13)
Это уравнение описывает линейную зависимость логарифма одной величины ln от другой величины x . Поэтому критерием применимости степенной регрессии служит требование того, чтобы точки эмпирических данных одной величины x i и логарифмы другой величины lnу i находились ближе всего к прямой (4.13).
Логарифмическая регрессия.
Логарифмической зависимостью величины Y от величины Х называется зависимость вида:
=a +b· lnx . (4.14)
Это уравнение называется уравнением логарифмической регрессии Y на Х . Параметры а и b называются коэффициентами логарифмической регрессии .
Гиперболическая регрессия.
Гиперболической зависимостью величины Y от величины Х называется зависимость вида:
Это уравнение называется уравнением гиперболической регрессии Y на Х . Параметры а и b называются коэффициентами гиперболической регрессии и определяются методом наименьших квадратов. Применение этого метода приводит к формулам:
В формулах (4.16-4.17) суммирование проводится по индексу i от единицы до количества наблюдений n .
К сожалению, в Excel нет функции, вычисляющих коэффициенты гиперболической регрессии. В тех случаях, когда заведомо не известно, что измеряемые величины связаны обратной пропорциональностью, рекомендуется вместо уравнения гиперболической регрессии искать уравнение степенной регрессии, так в Excel имеется процедура ее нахождения. Если же между измеряемыми величинами предполагается гиперболическая зависимость, то коэффициенты ее регрессии придется вычислять с помощью вспомогательных расчетных таблиц и операций суммирования по формулам (4.16-4.17).



