Раздел Fuzzy Logic Toolbox. С.Д.Штовба
Эпименид Кносский с острова Крит – полумифический поэт и философ, живший в VI в. до н.э., однажды заявил: «Все критяне – лжецы!». Так как он и сам был критянином, то его помнят как изобре тателя так называемого критского парадокса.
В терминах аристотелевой логики, в которой утверждение не может быть одновременно истинным и ложным, и подобные самоотрицания не имеют смысла. Если они истинны, то они ложны, но если они ложны, то они истинны.
И здесь на сцену выходит нечеткая логика, где переменные могут быть частичными членами множеств. Истинность или ложность перестают быть абсолютными – утверждения могут быть частично истинными и частично ложными. Использование подобного подхода позволяет строго математически доказать, что парадокс Эпименида ровно на 50% истинен и на 50% ложен.
Таким образом, нечеткая логика в самой своей основе несовместима с аристотелевой логикой, особенно в отношении закона Tertium non datur («Третьего не дано» – лат.), который также называют законом исключения среднего1
. Если сформулировать его кратко, то звучит он так: если утверждение не является истинным, то оно является ложным. Эти постулаты настолько базовые, что их часто просто принимают на веру.
Более банальный пример пользы нечеткой логики можно привести в контексте концепции холода. Большинство людей способно ответить на вопрос: «Холодно ли вам сейчас?». В большинстве случаев (если вы разговариваете не с аспирантом-физиком) люди понимают, что речь не идет об абсолютной температуре по шкале Кельвина. Хотя температуру в 0 K можно, без сомнения, назвать холодом, но температуру в +15 C многие холодом считать не будут.
Но машины не способны проводить такую тонкую градацию. Если стандартом определения холода будет «температура ниже +15 C», то +14,99 C будет расцениваться как холод, а +15 C – не будет.
Теория нечетких множеств
Рассмотрим рис. 1. На нем представлен график, помогающий понять то, как человек воспринимает температуру. Температуру в +60 F (+12 C) человек воспринимает как холод, а температуру в +80 F (+27 C) – как жару. Температура в +65 F (+15 C) одним кажется низкой, другим – достаточно комфортной. Мы называем эту группу определений функцией принадлежности к множествам,описывающим субъективное восприятие температуры человеком.
Так же просто можно создать дополнительные множества, описывающие восприятие температуры человеком. Например, можно добавить такие множества, как «очень холодно» и «очень жарко». Можно описать подобные функции для других концепций, например, для состояний «открыто» и «закрыто», температуры в охладителе или температуры в башенном охладителе.
То есть нечеткие системы можно использовать как универсальный аппроксиматор (усреднитель) очень широкого класса линейных и нелинейных систем. Это не только делает более надежными стратегии контроля в нелинейных случаях, но и позволяет использовать оценки специалистов-экспертов для построения схем компьютерной логики.
Нечеткие операторы
Чтобы применить алгебру для работы с нечеткими значениями, нужно определить используемых операторов. Обычно в булевой логике используется лишь ограниченный набор операторов, с помощью которых и производится выполнение других операций: NOT (оператор «НЕ»), AND (оператор «И») и OR (оператор «ИЛИ»).
Можно дать множество определений для этих трех базовых операторов, три из которых приведены в таблице. Кстати, все определения одинаково справедливы для булевой логики (для проверки просто подставьте в них 0 и 1). В булевой логике значение FALSE («ЛОЖЬ») эквивалентно значению «0», а значение TRUE («ИСТИНА») эквивалентно значению «1». Аналогичным образом в нечеткой логике степень истинности может меняться в диапазоне от 0 до 1, поэтому значение «Холод» верно в степени 0,1, а операция NOT(«Холод») даст значение 0,9.
Вы можете вернуться к парадоксу Эпименида и постараться его решить (математически он выражается как A = NOT(A), где A – это степень истинности соответствующего утверждения). Если же вы хотите более сложную задачу, то попробуйте решить вопрос о звуке хлопка, производимого одной рукой…
Решение задач методами нечеткой логики
Лишь немногие клапаны способны открываться «чуть-чуть». При работе оборудования обычно используются четкие значения (например, в случае бимодального сигнала 0-10 В), которые можно получить, используя так называемое «решение задач методами нечеткой логики». Подобный подход позволяет преобразовать семантические знания, содержащиеся в нечеткой системе, в реализуемую стратегию управления2.
Это можно сделать с использованием различных методик, но для иллюстрации процесса в целом рассмотрим всего один пример.
В методе height defuzzification результатом является сумма пиков нечетких множеств, рассчитываемая с использованием весовых коэффициентов. У этого метода есть несколько недостатков, включая плохую работу с несимметричными функциями принадлежности к множествам, но у него есть одно преимущество – этот метод наиболее простой для понимания.
Предположим, что набор правил, управляющих открытием клапана, даст нам следующий результат:
«Клапан частично закрыт»: 0,2
«Клапан частично открыт»: 0,7
«Клапан открыт»: 0,3
Если мы используем метод height defuzzification для определения степени открытости клапана, то получим результат:
«Клапан закрыт»: 0,1
(0,1*0% + 0,2*25% + 0,7*75% + 0,3*100%)/ /(0,1 + 0,2 + 0,7 + 0,3) =
= (0% + 5% + 52,5% + 30%)/(1,3) = = 87,5/1,3 = = 67,3%,
т.е. клапан необходимо открыть на 67,3%.
Практическое применение нечеткой логики
Когда только появилась теория нечеткой логики, в научных журналах можно было найти статьи, посвященные ее возможным областям применения. По мере продвижения разработок в данной области число практических применений для нечеткой логики начало быстро расти. В настоящее время этот список был бы слишком длинным, но вот несколько примеров, которые помогут понять, насколько широко нечеткая логика используется в системах управления и в экспертных системах3.
– Устройства для автоматического поддержания скорости движения автомобиля и увеличения эффективности/стабильности работы автомобильный двигателей (компании Nissan, Subaru).
Свое начало математическая теория нечетких множеств
(fuzzy sets) и сама нечеткая логика
(fuzzy logic) ведет с 1965 года. Ее отцом-основателем является профессор Лотфи Заде (Lotfi Zadeh) из университета Беркли, именно он в своей статье «Fuzzy Sets» в журнале Information and Control и ввел оба этих понятия. Данный математический аппарат позволил ввести в такую точную науку, как математика, нечеткие (размытые) понятия, которыми оперирует любой человек, и заложил основу принципиально новым методам решения задач на основе мягких вычислений . Все эти нововведения, при правильном их использовании, могут значительно облегчить процесс решения задач классификации, создания экспертных систем и построения нейронных сетей.
Однако практическое применение нечеткой логики этим не ограничилось, в действительности свое наибольшее распространение данный математический аппарат получил в теории автоматического управления . Именно с этим и можно связать появление еще одного нового понятия - нечеткой модели
. Нечеткая модель - это частный случай математической модели .
1. Теория нечетких множеств и нечеткой логики
Новая теория Лотфи Заде в некотором роде расширяет привычные нам границы математической логики и теории множеств. Математическая логика способна работать только со строго формализованными данными, а принадлежность объекта к тому или иному множеству определяется лишь двумя понятиями, то есть само понятие "принадлежность" - дискретная величина, способная принимать два значения:
- "1" - если объект принадлежит тому или иному множеству;
- "0" - если не принадлежит.
В своей теории нечетких множеств Лотфи Заде отошел от дискретного понятия "принадлежности" и ввел новое - "степень принадлежности", а привычные "множества" были заменены на "нечеткие множества".
1.1. Основные термины и определения
Определение 1. Нечетким множеством (fuzzy set) на универсальном множестве называется совокупность пар , где - степень принадлежности элемента нечеткому множеству.
Определение 2.
Степень принадлежности
- это число из диапазона . Чем выше степень принадлежности, тем в большей мере элемент универсального множества соответствует свойствам данного нечеткого множества. Так, если степень принадлежности равна 0, то данный элемент абсолютно не соответствует множеству, а если равна 1, то можно говорить, наоборот, о полном соответствии. Эти два случая являются краевыми и в отсутствии иных вариантов представляли бы из себя обычное множество. Наличие всех остальных вариантов и есть ключевое отличие нечеткого множества.
Определение 3.
Функцией принадлежности
(membership function)
называется функция, которая позволяет вычислить степень принадлежности произвольного элемента универсального множества нечеткому множеству. Следовательно, область значений функций принадлежности должна принадлежать диапазону . В большинстве случаев функция принадлежности - это монотонная непрерывная функция.
Определение 4.
Лингвистической (нечеткой) переменной (linguistic variable)
называется переменная, значениями которой могут быть слова или словосочетания некоторого естественного или искусственного языка. Именно из лингвистических переменных и состоят нечеткие множества. При определении нечеткого множества количество и характер нечетких переменных субъективны для каждой отдельной задачи.
Определение 5. Терм–множеством (term set) называется множество всех возможных значений, которые способна принимать лингвистическая переменная.
Определение 6. Термом (term) называется любой элемент терм–множества. В теории нечетких множеств терм формализуется нечетким множеством с помощью функции принадлежности. Функция принадлежности для каждого термина индивидуальна и зачастую уникальна. Существуют различные методы построения этих функций: прямые , косвенные и методы относительных частот . В их основе зачастую лежат характерные точки функции принадлежности или эмпирические данные эксперта данной предметной области.
Пример:
Определим некоторую лингвистическую переменную с названием "Возраст". По определению "Возраст" - период, ступень в развитии и росте человека, животного, растения. Минимальное значение этой переменной равно 0, то есть человеку не исполнилось и года. В качестве максимального значения возьмем 80. В зависимости от конкретного возраста человека мы можем дать оценку: "новорожденный", "юный", "молодой", "среднего", "старый", "пожилой" и так далее. Этот список может вместить в себя довольно большое количество элементов. Он будет являться терм-множеством для нашей лингвистической переменной, а его элементами - термами.
На рисунке ниже приведен пример нечеткой переменной "Возраст", для которой задали терм-множество только из трех термов: "Юный", "Средний", "Старый". Каждый из термов имеет свою функцию принадлежности.
Рассмотрим случай, когда возраст человека равен 30 годам, что на рисунке будет соответствовать перпендикуляру, проведенному из точки (30, 0). Эта прямая будет пересекать все три функции принадлежности в точках:
- (30, 0) - точка пересечения графика "Возраст 30 лет" и графика "Старый".
- (30, 0.29) - точка пересечения графика "Возраст 30 лет" и графика "Средний".
- (30, 0.027) - точка пересечения графика "Возраст 30 лет" и графика "Юный".

Из координат этих трех точек можно сделать вывод, что человека в 30 лет никак нельзя назвать старым, а если выбирать между юным и средним возрастом, то преобладает второе. Степень принадлежности к терму "Средний" равна 0.29, что довольно мало, и в действительности для человека в 30 лет куда лучше подошел бы иной терм, например "Молодой".
Определение 7. Дефаззификацией (defuzzification) называется процедура преобразования нечеткого множества в четкое число. На данный момент выделяют более двадцати методов, причем их результаты могут весьма значимо отличаться друг от друга. Следует отметить, что лучшие результаты дает дефаззификации по методу центра тяжести (center of gravity).
1.2. Нечеткая логика
Нечеткая логика - это обобщение традиционной аристотелевой логики на случай, когда истинность рассматривается как лингвистическая переменная. Как и в классической логике, для нечеткой логики определены свои нечеткие логические операции над нечеткими множествами. Для нечетких множеств существуют все те же операции, что и для обычных множеств, только их вычисление на порядок сложнее. Отметим также, что композиция нечетких множеств - есть нечеткое множество.
Основными особенностями нечеткой логики, отличающими ее от классической, являются максимальная приближенность к отражению реальности и высокий уровень субъективности, вследствие чего могут возникнуть значительные погрешности в результатах вычислений с ее использованием.
Нечеткая модель - математическая модель, в основе вычисления которой лежит нечеткая логика. К построению таких моделей прибегают в случае, когда предмет исследования имеет очень слабую формализацию, и его точное математическое описание слишком сложное или просто не известно. Качество выходных значений этих моделей (погрешность модели) напрямую зависит только от эксперта, который составлял и настраивал модель. Для минимизации ошибки лучшим вариантом будет составление максимально полной и исчерпывающей модели и последующая ее настройка средствами машинного обучения на большой обучающей выборке.
Ход построения модели можно разделить на три основных этапа:
- Определение входных и выходных параметров модели.
- Построение базы знаний.
- Выбор одного из методов нечеткого логического вывода.
От первого этапа непосредственно зависят два других, и именно он определяет будущее функционирование модели. База знаний или, как по-другому ее называют, база правил - это совокупность нечетких правил вида: "если, то", определяющих взаимосвязь между входами и выходами исследуемого объекта. Количество правил в системе не ограниченно и также определяется экспертом. Обобщенный формат нечетких правил такой:
Если условие (посылка) правила, то заключение правила.
Условие правила
характеризует текущее состояние объекта, а заключение
- то, как это условие повлияет на объект. Общий вид условий и заключений нельзя выделить, так как они определяются нечетким логическим выводом.
Каждое правило в системе имеет вес -
данный параметр характеризует значимость правила в модели. Весовые коэффициенты присваиваются правилу в диапазоне . Во многих примерах нечетких моделей, которые можно встретить в литературе, данные веса не указаны, но это не означает, что их нет, в действительности для каждого правила из базы в таком случае вес фиксирован и равен единице. Условия и заключения для каждого правила могут быть двух видов:
- простое - в нем участвует одна нечеткая переменная;
- составное - участвуют несколько нечетких переменных.
В зависимости от созданной базы знаний для модели определяется система нечеткого логического вывода. Нечетким логическим выводом называется получение заключения в виде нечеткого множества, соответствующего текущим значениях входов, с использованием нечеткой базы знаний и нечетких операций. Двумя основными типами нечеткого логического вывода являются Мамдани и Сугено.
1.3. Нечеткий логический вывод Мамдани
Нечеткий логический вывод по алгоритму Мамдани выполняется по нечеткой базе знаний:

Значения входных и выходной переменной в ней заданы нечеткими множествами.
v
нечеткому терму t.
j-го правила из базы знаний;
где - операция из s-нормы (t-нормы), т.е. из множества реализаций логической операции ИЛИ (И). Наиболее часто используются следующие реализации: для операции ИЛИ - нахождение максимума и для операции И - нахождение минимума.
m
Особенностью этого нечеткого множества является то, что универсальным множеством для него является терм-множество выходной переменной .
Иными словами, используя термины нечеткой логики, произвести импликацию и агрегацию условий. Импликация моделируется двумя методами: нахождением минимума или произведения множеств, агрегация - нахождением максимума или суммы множеств.
После этого мы получим результирующее нечеткое множество, дефаззификация которого и даст нам точный выход системы.
1.4. Нечеткий логический вывод Сугено
Нечеткий логический вывод по алгоритму Сугено выполняется по нечеткой базе знаний:

База знаний Сугено аналогична базе знаний Мамдани за исключением заключений правил , которые задаются не нечеткими термами, а линейной функцией от входов:
Правила в базе знаний Сугено являются своего рода переключателями с одного линейного закона "входы - выход" на другой, тоже линейный. Границы подобластей размытые, следовательно, одновременно могут выполняться несколько линейных законов, но с различными степенями.
Эту базу также можно записать как:
Введем новое обозначение: - функция принадлежности входной или выходной нечеткой переменной v
нечеткому терму t.
Степени принадлежности входного вектора нечетким термам из базы знаний рассчитываются следующим образом:
Данная функция будет характеризовать результат работы j-го правила из базы знаний;
где - операция из s-нормы (t-нормы), т.е. из множества реализаций логической операции ИЛИ (И). В нечетком логическом выводе Сугено наиболее часто используются следующие реализации треугольных норм: вероятностное ИЛИ как s-норма и произведение как t-норма.
После нахождения для мы получим m новых функций принадлежности, которые в совокупности будут образовывать новое нечеткое множество, обозначим его , соответствующее входному вектору .
Обратим внимание, что в отличие от результата вывода Мамдани, приведенное выше нечеткое множество является обычным нечетким множеством первого порядка. Оно задано на множестве четких чисел. Результирующее значение выхода определяется как суперпозиция линейных зависимостей, выполняемых в данной точке n- мерного факторного пространства. Для этого дефаззифицируют нечеткое множество , находя взвешенное среднее или взвешенную сумму .
2. Библиотека нечеткой логики FuzzyNet
На практике создание и работа даже с очень простой нечеткой моделью - весьма непростая задача, однако имеется множество различных программных средств и библиотек, которые существенно ее упрощают. Рассмотрим на примерах тестовых скриптов из библиотеки FuzzyNet для MQL5 процесс создания и работы с двумя нечеткими моделями.
2.1. Проектирование систем типа Мамдани
Первый пример - скрипт Tips_Sample_Mamdani.mq5
из библиотеки FuzzyNet для MQL5. В нем реализована нечеткая модель для вычисления чаевых, которые посетителю заведения предпочтительнее оставить, опираясь на свою оценку качества обслуживания и еды. Данная система имеет два нечетких логических входа, один выход, базу знаний из трех правил и систему логического вывода типа Мамдани.
Входными параметрами будут нечеткие переменные "еда" (food ) и "сервис" (service ), обе переменные оцениваются по шкале от 0 до 10 - это их минимальные и максимальные значения. Переменная "еда" состоит из двух термов: "невкусная" (rancid ), "вкусная" (delicious ). Переменная "сервис" будет состоять из трех нечетких термов: "плохой" (poor ), "хороший" (good ), "отличный" (excellent ).
На выходе получим нечеткую переменную "чаевые" (tips
). Определим диапазон значений оставляемых чаевых от 5 до 30% процентов от суммы в чеке и заведем для этой переменной три терма: "маленькие" (cheap
), "средние" (average
), "большие" (generous
).
База знаний этой системы будет состоять из трех правил:
- Если (сервис плохой) или (еда невкусная), то чаевые маленькие.
- Если (сервис хороший), то чаевые средние.
- Если (сервис отличный) или (еда вкусная), то чаевые большие.
Теперь, имея общие представления о системе, рассмотрим процесс ее создания:
- Подключим файл MamdaniFuzzySystem.mqh из библиотеки FuzzyNet для MQL5:
#include - Теперь мы можем создать пустую систему Мамдани и далее ее наполнять:
MamdaniFuzzySystem *fsTips=new MamdaniFuzzySystem(); - Создадим первую входную переменную "сервис". При создании нечетких переменных в качестве параметров для конструктора указывается сначала имя переменной в виде строки, затем ее минимальное и максимальное значение.
FuzzyVariable *fvService=new FuzzyVariable("service" ,0.0 ,10.0 ); - Добавим в нее нечеткие термы. В качестве параметров конструктор нечетких терминов принимает первым параметром имя в виде строки, а вторым - соответствующую ему функцию принадлежности.
fvService.Terms().Add(new FuzzyTerm("poor" , new TriangularMembershipFunction(-5.0 , 0.0 , 5.0 ))); fvService.Terms().Add(new FuzzyTerm("good" , new TriangularMembershipFunction(0.0 , 5.0 , 10.0 ))); fvService.Terms().Add(new FuzzyTerm("excellent" , new TriangularMembershipFunction(5.0 , 10.0 , 15.0 ))); Функции принадлежности в данном примере для всех термов представлены в виде треугольной функции. - Теперь уже готовую и сформированную нечеткую переменную добавляем в нашу систему:
fsTips.Input().Add(fvService); - Аналогично реализуем второй вход для системы с переменной "еда", только термины для этой переменной будут иметь трапециевидную функцию принадлежности.
FuzzyVariable *fvFood=new FuzzyVariable("food" ,0.0 ,10.0 ); fvFood.Terms().Add(new FuzzyTerm("rancid" , new TrapezoidMembershipFunction(0.0 , 0.0 , 1.0 , 3.0 ))); fvFood.Terms().Add(new FuzzyTerm("delicious" , new TrapezoidMembershipFunction(7.0 , 9.0 , 10.0 , 10.0 ))); fsTips.Input().Add(fvFood); - Поскольку система имеет логический вывод Мамдани, ее входные и выходные значения будет определяться одними и теми же способами. Поэтому по аналогии создадим выход:
FuzzyVariable *fvTips=new FuzzyVariable("tips" ,0.0 ,30.0 ); fvTips.Terms().Add(new FuzzyTerm("cheap" , new TriangularMembershipFunction(0.0 , 5.0 , 10.0 ))); fvTips.Terms().Add(new FuzzyTerm("average" , new TriangularMembershipFunction(10.0 , 15.0 , 20.0 ))); fvTips.Terms().Add(new FuzzyTerm("generous" , new TriangularMembershipFunction(20.0 , 25.0 , 30.0 ))); fsTips.Output().Add(fvTips); - Создадим нечеткие правила, которые в совокупности будут представлять базу знаний нашей системы. Для создания правила необходимо вызвать метод ParseRule
от объекта, который представляет нашу систему, и в качестве параметра передать ему простое строковое представление нечеткого правила:
MamdaniFuzzyRule *rule1 = fsTips.ParseRule("if (service is poor) or (food is rancid) then (tips is cheap)" ); MamdaniFuzzyRule *rule2 = fsTips.ParseRule("if (service is good) then (tips is average)" ); MamdaniFuzzyRule *rule3 = fsTips.ParseRule("if (service is excellent) or (food is delicious) then (tips is generous)" );Написание нечетких правил строго типизировано и не допускает использование неключевых слов. Ключевыми словами являются: "if", "then", "is", "and", "or", "not", "(" , ")", "slightly", "somewhat", "very", "extremely". Последние четыре ключевых слова являются лингвистическими квантификаторами. Также к ключевым словам относятся все имена переменных, терминов и функций, имеющихся в вашей системе. Лингвистическими квантификаторами увеличивают или, наоборот, уменьшают значимость нечетких термов или линейных функций Сугено. Реализация лингвистических квантификаторов:
- "slightly" - "едва", заменяет результат посылки на ее кубический корень. Сильно уменьшает значимость.
- "somewhat" - "отчасти", заменяет результат посылки на ее квадратный корень. Уменьшает значимость.
- "very" - "очень", возводит результат посылки во вторую степень. Увеличивает значимость.
- "extremely" - "экстремально", возводит результат посылки в третью степень. Сильно увеличивает значимость.
- Осталось лишь добавить правила в систему:
fsTips.Rules().Add(rule1); fsTips.Rules().Add(rule2); fsTips.Rules().Add(rule3);
Теперь мы имеем готовую модель вычисления чаевых на основе системы нечеткого логического вывода Мамдани.
2.2. Проектирование систем типа Сугено
Примером реализации системы типа Сугено будет скрипт для вычисления необходимого управления системой круиз-контроля автомобиля. Этот скрипт описан в файле Cruise_Control_Sample_Sugeno.mq5
библиотеки FuzzyNet для MQL5 и является одним из примеров применения нечетких моделей для решения задач автоматического управления.
Именно для таких одномерных задач в системах автоматического управления (САУ) и нашла наибольшее распространение нечеткая логика. Постановка этих задач звучит примерно так: некий объект в момент времени находится в состоянии "A", необходимо, чтобы за время он пришел в состояние "B". Для решения задач такого типа весь временной участок разбивают на частей, находят шаг по времени, равный , и далее САУ необходимо вырабатывать управление в каждой точке , где i=0,1,2...n .
С данной задачей легко справляются различные ПИД -регуляторы , но у них есть один существенный недостаток - они не могут выработать, скажем так, "плавное" управление. То есть если построить систему круиз-контроля автомобиля на основе ПИД-регулятора, при изменении скорости эта система выведет вас на заданную, но при этом могут быть различные рывки и толчки. Нечеткий регулятор сможет выполнить все гораздо плавнее и комфортнее с точки зрения человека.
Становится очевидным, что на выходе нашего нечеткого регулятора будет необходимое изменение скорости в виде ускорения, а на входе будет ошибка и первая производная по ошибке. Ошибка - отклонение текущего состояния от желаемого. Иными словами, на вход системы будут поступать следующие сведения:
- разность между скоростью автомобиля в данный момент и скоростью, установленной в системе круиз-контроля;
- как быстро эта разность уменьшается (увеличивается).
Итак, первый входной параметр "ошибка скорости" (SpeedError
) будет принимать значения от -20 до 20 км/ч и иметь три терма: "уменьшилась" (slower
), "не изменилась" (zero
), "увеличилась" (faster
). Все три терма будут иметь треугольную функцию принадлежности. Второй вход - "производная по ошибке скорости" (SpeedErrorDot
) с диапазоном от -5 до 5 и нечеткими термами "уменьшилась" (slower
), "не изменилась" (zero
), "увеличилась" (faster
) также с треугольной функцией принадлежности.
Поскольку наша модель имеет систему логического вывода Сугено, выходное значение "ускорение" (Accelerate ) не будет иметь максимального и минимального значения, а вместо нечетких терминов будут линейные комбинации входных переменных, которые также будут иметь имена: "не изменять" (zero ), "увеличить" (faster ), "уменьшить" (slower ), "поддерживать" (func ). Распишем все четыре линейные комбинации. Для этого обозначим переменные SpeedError как , SpeedErrorDot как , а Accelerate как , тогда получим уравнения:
База знаний этой системы будет состоять из девяти правил:
- Если (ошибка уменьшилась) и (производная по ошибке уменьшилась), то ускорение увеличить.
- Если (ошибка уменьшилась) и (производная по ошибке не изменилась), то ускорение увеличить.
- Если (ошибка уменьшилась) и (производная по ошибке увеличилась), то ускорение не изменять.
- Если (ошибка не изменилась) и (производная по ошибке уменьшилась), то ускорение увеличить.
- Если (ошибка не изменилась) и (производная по ошибке не изменилась), то ускорение поддерживать.
- Если (ошибка не изменилась) и (производная по ошибке увеличилась), то ускорение уменьшить.
- Если (ошибка увеличилась) и (производная по ошибке уменьшилась), то ускорение увеличить.
- Если (ошибка увеличилась) и (производная по ошибке не изменилась), то ускорение уменьшить.
- Если (ошибка увеличилась) и (производная по ошибке увеличилась), то ускорение уменьшить.
Рассмотрим непосредственно ход создания системы:
- Подключим файл SugenoFuzzySystem.mqh из библиотеки FuzzyNet для MQL5:
#include - Теперь мы можем создать пустую систему Сугено и далее ее наполнять:
SugenoFuzzySystem *fsCruiseControl=new SugenoFuzzySystem(); - Входные переменные для системы Сугено создаются так же, как и для системы типа Мамдани.
Создадим переменную "ошибка скорости" и добавим ее в систему:
FuzzyVariable *fvSpeedError=new FuzzyVariable("SpeedError" ,-20.0 ,20.0 ); fvSpeedError.Terms().Add(new FuzzyTerm("slower" ,new TriangularMembershipFunction(-35.0 ,-20.0 ,-5.0 ))); fvSpeedError.Terms().Add(new FuzzyTerm("zero" , new TriangularMembershipFunction(-15.0 , -0.0 , 15.0 ))); fvSpeedError.Terms().Add(new FuzzyTerm("faster" , new TriangularMembershipFunction(5.0 , 20.0 , 35.0 )));
Создадим переменную "изменение ошибки скорости" и также добавим ее в систему:
FuzzyVariable *fvSpeedErrorDot=new FuzzyVariable("SpeedErrorDot" ,-5.0 ,5.0 ); fvSpeedErrorDot.Terms().Add(new FuzzyTerm("slower" , new TriangularMembershipFunction(-9.0 , -5.0 , -1.0 ))); fvSpeedErrorDot.Terms().Add(new FuzzyTerm("zero" , new TriangularMembershipFunction(-4.0 , -0.0 , 4.0 ))); fvSpeedErrorDot.Terms().Add(new FuzzyTerm("faster" , new TriangularMembershipFunction(1.0 , 5.0 , 9.0 )));
- Создадим нечеткую переменную типа Сугено, которая будет являться выходом системы. При создании нечеткой переменной конструктор принимает лишь один параметр - ее имя. Далее в нее можно добавлять линейные функции, но прежде эти функции нужно определить, а для этого нужен массив коэффициентов типа double .
Формирование линейной функции осуществляется следующим образом: каждая входная переменная будет являться неизвестной уравнения с коэффициентом, полученным из массива коэффициентов. Таким образом, коэффициенты в массиве должны располагаться в том порядке, в котором заносились входные переменные. Так, при первой входной переменной будет коэффициент с индексом 0, при второй - с индексом 1 и так далее. Поэтому длина массива коэффициентов должна быть больше на единицу или равна количеству входных переменных. Если длины равны, то коэффициент при свободном члене будет равен нулю, иначе его значение будет равно последнему элементу массива.
В нашей системе две входные переменные, поэтому длины массивов коэффициентов не должны превышать трех. Объявим все четыре массива, на их основе сформируем описанные выше функции и добавим их в нечеткую переменную типа Сугено, а ее, в свою очередь, занесем в систему:
SugenoVariable *svAccelerate=new SugenoVariable("Accelerate" ); double coeff1={0.0 ,0.0 ,0.0 }; svAccelerate.Functions().Add(fsCruiseControl.CreateSugenoFunction("zero" ,coeff1)); double coeff2={0.0 ,0.0 ,1.0 }; svAccelerate.Functions().Add(fsCruiseControl.CreateSugenoFunction("faster" ,coeff2)); double coeff3={0.0 ,0.0 ,-1.0 }; svAccelerate.Functions().Add(fsCruiseControl.CreateSugenoFunction("slower" ,coeff3)); double coeff4={-0.04 ,-0.1 ,0.0 }; svAccelerate.Functions().Add(fsCruiseControl.CreateSugenoFunction("func" ,coeff4)); fsCruiseControl.Output().Add(svAccelerate); - По аналогии с системой Мамдани создадим все девять нечетких правил:
SugenoFuzzyRule *rule1 = fsCruiseControl.ParseRule("if (SpeedError is slower) and (SpeedErrorDot is slower) then (Accelerate is faster)" ); SugenoFuzzyRule *rule2 = fsCruiseControl.ParseRule("if (SpeedError is slower) and (SpeedErrorDot is zero) then (Accelerate is faster)" ); SugenoFuzzyRule *rule3 = fsCruiseControl.ParseRule("if (SpeedError is slower) and (SpeedErrorDot is faster) then (Accelerate is zero)" ); SugenoFuzzyRule *rule4 = fsCruiseControl.ParseRule("if (SpeedError is zero) and (SpeedErrorDot is slower) then (Accelerate is faster)" ); SugenoFuzzyRule *rule5 = fsCruiseControl.ParseRule("if (SpeedError is zero) and (SpeedErrorDot is zero) then (Accelerate is func)" ); SugenoFuzzyRule *rule6 = fsCruiseControl.ParseRule("if (SpeedError is zero) and (SpeedErrorDot is faster) then (Accelerate is slower)" ); SugenoFuzzyRule *rule7 = fsCruiseControl.ParseRule("if (SpeedError is faster) and (SpeedErrorDot is slower) then (Accelerate is faster)" ); SugenoFuzzyRule *rule8 = fsCruiseControl.ParseRule("if (SpeedError is faster) and (SpeedErrorDot is zero) then (Accelerate is slower)" ); SugenoFuzzyRule *rule9 = fsCruiseControl.ParseRule("if (SpeedError is faster) and (SpeedErrorDot is faster) then (Accelerate is slower)" ); - Добавим их в нашу систему:
fsCruiseControl.Rules().Add(rule1); fsCruiseControl.Rules().Add(rule2); fsCruiseControl.Rules().Add(rule3); fsCruiseControl.Rules().Add(rule4); fsCruiseControl.Rules().Add(rule5); fsCruiseControl.Rules().Add(rule6); fsCruiseControl.Rules().Add(rule7); fsCruiseControl.Rules().Add(rule8); fsCruiseControl.Rules().Add(rule9);
2.3. Расчет систем типа Мамдани и Сугено
На вход нечеткой системы должна подаваться нечеткая переменная и ее значение. Как говорилось выше, нечеткие переменные принимают значения из их терм-множества. Следовательно, результат вычисления системы будет зависть от функций принадлежности, которые соответствуют термам, поданным на вход, при нечетких входных переменных. Однако в большинстве случаев на вход системы посылают нечеткие переменные в виде простых числовых значений и на выходе хотят получить точный результат в таком же виде. В этом случае получается так, что нечеткий терм не имеет явного объявления, а его функция принадлежности представляется как константная функция принадлежности. Именно с этим частным случаем и работают системы, написанные с использованием библиотеки FuzzyNet.
Что же именно нужно подавать на вход системы и в каком виде мы получим результат от нее?
Количество входных переменных для нечетких систем не ограниченно, каждый вход обязательно должен принимать какие-то значения, следовательно, мы должны иметь список, в котором будем хранить значения для каждого входа. Элементами этого списка должен быть сложный объект с двумя полями: первое - нечеткая переменная, а второе - числовое значение типа double
. В файле Dictionary.mqh из библиотеки FuzzyNet на MQL5 реализован класс Dictionary_Obj_Double
, позволяющий создавать такие объекты.
Сформируем входной список для нашей системы типа Мамдани:
CList *in =new CList; Dictionary_Obj_Double *p_od_Service=new Dictionary_Obj_Double; Dictionary_Obj_Double *p_od_Food=new Dictionary_Obj_Double; p_od_Service.SetAll(fvService, Service); p_od_Food.SetAll(fvFood, Food); in .Add(p_od_Service); in .Add(p_od_Food);
Здесь Service и Food - два входных параметра типа double .
В описанных выше примерах обе системы, как Мамдани так и Сугено, имеют лишь по одному выходу, хотя в общем случае, как и на входы, никаких ограничений на их количество нет. Структура входа и выхода ничем не отличается.
Выход для системы типа Мамдани:
CList *result=new CList; Dictionary_Obj_Double *p_od_Tips=new Dictionary_Obj_Double;
Теперь для каждой системы вызываем функцию Calculate
, которая принимает один параметр - список входов, а возвращает список выходов. По индексу 0 из этого списка получим значения выхода системы, который представлен как объект класса Dictionary_Obj_Double.
Используя методы Key
и Value
для данного объекта, можно получить переменную и ее результат соответственно.
Выполним расчет для системы Мамдани и выведем на экран полученное число при нечеткой выходной переменной fvTips :
Result=fsTips.Calculate(in); p_od_Tips=result.GetNodeAtIndex(0 ); Alert ("Tips, %: " ,p_od_Tips.Value());
Проделаем то же самое с системой типа Сугено:
CList *in =new CList; Dictionary_Obj_Double *p_od_Error=new Dictionary_Obj_Double; Dictionary_Obj_Double *p_od_ErrorDot=new Dictionary_Obj_Double; p_od_Error.SetAll(fvSpeedError,Speed_Error); p_od_ErrorDot.SetAll(fvSpeedErrorDot,Speed_ErrorDot); in .Add(p_od_Error); in .Add(p_od_ErrorDot); CList *result=new CList; Dictionary_Obj_Double *p_od_Accelerate=new Dictionary_Obj_Double; result=fsCruiseControl.Calculate(in ); p_od_Accelerate=result.GetNodeAtIndex(0 ); Alert("Accelerate, %: " ,p_od_Accelerate.Value()*100 );
Заключение
Более подробно ознакомиться со скриптами, описанными выше, а также создать свою нечеткую модель вы можете, скачав библиотеку FuzzyNet для MQL5 или MQL4 . Важно понимать, что построение "боевых" нечетких моделей - это довольно непростая работа, даже с использованием каких-либо вспомогательных библиотек, а каждая готовая модель требует обязательной доскональной проверки и настройки.
Более подробное и объемное описание нечетких регуляторов.
Математическая теория нечетких множеств (fuzzy sets) инечеткая логика (fuzzy logic ) являются обобщениями классическойтеории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких иприближенных рассуждений при описании человеком процессов, систем, объектов.
Одной из основных характеристик нечеткой логики является лингвистическая переменная, которая определяется набором вербальных (словесных) характеристик некоторого свойства. Рассмотрим лингвистическую переменную «скорость», которую можно характеризовать через набор следующих понятий-значений: «малая», «средняя» и «большая», данные значения называются термами.
Следующей основополагающей характеристикой нечеткой логики является понятие функции принадлежности. Функция принадлежности определяет, насколько мы уверены в том, что данное значение лингвистической переменной (например, скорость) можно отнести к соответствующим ей категориям (в частности для лингвистической переменной скорость к категориям «малая», «средняя», «большая»).
На следующем рисунке (первая часть) отражено, как одни и те же значения лингвистической переменной могут соответствовать различным понятиям-значениям или термам. Тогда функции принадлежности, характеризующие нечеткие множества понятий скорости, можно выразить графически, в более привычном математическом виде (рис. 35, вторая часть).

Из рисунка видно, что степень, с которой численное значение скорости, например v = 53, совместимо с понятием «большая», есть 0,7, в то время как совместимость значений скорости, равных 48 и 45, с тем же понятием есть 0,5 и 0,1 соответственно.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:

При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):

При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
 Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
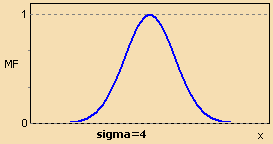
Функция принадлежности гауссова типа описывается формулой
![]()
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.
 Рисунок
2. Гауссова функция принадлежности.
Рисунок
2. Гауссова функция принадлежности.
Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке приведен пример описанной лингвистической переменной "Цена акции".
 Рис.
Описание лингвистической переменной
"Цена акции".
Рис.
Описание лингвистической переменной
"Цена акции".
Количество термов в лингвистической переменной редко превышает 7.
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
Существует хотя бы одно правило для каждого лингвистического терма выходной переменной .
Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида: R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1 … R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i … R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m , где x k , k=1..n – входные переменные; y – выходная переменная; A ik – термы соответствующих переменных с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
 Рисунок
5. Система нечеткого логического вывода.
Рисунок
5. Система нечеткого логического вывода.
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
![]()
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
![]()
где MF(y) – функция принадлежности итогового нечеткого множества.
4. Дефазификация, или приведение к четкости. Под дефаззификацией понимается процедура преобразования нечетких величин, получаемых в результате нечеткого вывода, в четкие. Эта процедура является необходимой в тех случаях, где требуется интерпретация нечетких выводов конкретными четкими величинами, т.е. когда на основе функции принадлежности возникает потребность определить для каждой точки вZ числовые значения.
В настоящее время отсутствует систематическая процедура выбора стратегии дефаззификации. На практике часто используют два наиболее общих метода: метод центра тяжести (ЦТ - центроидный), метод максимума (ММ).
Для дискретных пространств в центроидном методе формула для вычисления четкого значения выходной переменной представляется в следующем виде:
Стратегия дефаззификации ММ предусматривает подсчет всех тех z , чьи функции принадлежности достигли максимального значения. В этом случае (для дискретного варианта) получим
где z - выходная переменная, для которой функция принадлежности достигла максимума;m - число таких величин.
Из этих двух наиболее часто используемых стратегий дефаззификации, стратегия ММ дает лучшие результаты для переходного режима, аЦТ - в установившемся режиме из-за меньшей среднеквадратической ошибки.
Пример нечеткого правила

Как работает.
По максимальному значению функций принадлежности (для скорости 60 км в час значение функции принадлежности «низкая» = 0, а для дорожных условий 75 % от нормы значение функции принадлежности «тяжелые» = около 0.7) по 0.7 проводится прямая которая рассекает геометрическую фигуру заключения (подача топлива) на две части, в результате берется фигура лежащая ниже прямой а верхняя часть отбрасывается. Это для одного правила, таких правил может быть 100 и более в реальных задачах.
Рассмотрим процесс получения нечеткого вывода по трем правилам одновременно с последующим получением четкого решения. Данная процедура включает в себя три этапа. На первом этапе получают нечеткие выводы по каждому из правил в отдельности по схеме, показанной на рис. 3.13. На втором этапе производится сложение результирующих функций, полученных на предыдущем этапе (применяется логическая операция ИЛИ, т.е. берется максимум). Третий этап - этап получения четкого решения (дефаззификация). Здесь применяется любой из известных классических методов: метод центра тяжести и т.д. Полученное в виде числового значения четкое решение служит задающей величиной системы управления. В нашем примере это будет величина, в соответствии с которой ИСУ должна будет изменить подачу топлива. Процесс получения нечетких выводов по нескольким правилам с последующей дефаззификацией для рассматриваемого примера показан на рис. 3.14. При начальном значении скорости = 65 км в час, и дорожным условиям = 80 % от норматива получаем следующую схему решения об уровне подачи топлива.

Рис. 3.14. Процесс получения нечетких выводов по правилам и их преобразование в четкое решение.
Как видно из рис. 3.14, в результате дефаззификации получено четкое решение: при заданных значениях скорости и дорожных условий подача топлива должна составлять 63% от
максимального значения. Таким образом, несмотря на нечеткость выводов, в итоге получено вполне четкое и определенное решение. Такое решение, вероятно, принял бы и водитель автомобиля в процессе движения. Данный пример демонстрирует великолепные возможности моделирования человеческих рассуждений на основе методов теории нечетких множеств.
Классическая логика по определению не может оперировать с нечетко очерченными понятиями, поскольку все высказывания в формальных логических системах могут иметь только два взаимоисключающих состояния: «истина» со значением истинности «1» и «ложь» со значением истинности «0». Одной из попыток уйти от двузначной бинарной логики для описания неопределенности было введение Лукашевичем трехзначной логики с третьим состоянием «возможно» со значением истинности «0,5». Введя в рассмотрение нечеткие множества, Заде предложил обобщить классическую бинарную логику на основе рассмотрения бесконечного множества значений истинности. В предложенном Заде варианте нечеткой логики множество значений истинности высказываний обобщается до интервала 0 ; 1 , т.е. включает как частные случаи классическую бинарную логику и трехзначную логику Лукашевича. Такой подход позволяет рассматривать высказывания с различными значениями истинности и выполнять рассуждения с неопределенностью.
Нечеткое высказывание – это законченная мысль, об истинности или ложности которой можно судить только с некоторой степенью уверенности 0 ; 1: «возможно истинно», «возможно ложно» и т.п. Чем выше уверенность в истинности высказывания, тем ближе значение степени истинности к 1 . В предельных случаях 0 , если мы абсолютно уверены в ложности высказывания, и 1 , если мы абсолютно уверены в истинности высказывания, что соответствует классической бинарной логике. В нечеткой логике нечеткие высказывания обозначаются так же, как и нечеткие множества: A , B , C … . Введем нечеткое отображение T: Ω → 0 ; 1 , которое действует на множестве нечетких высказываний Ω = A , B , C … . В этом случае значение истинности высказывания A ∈ Ω определяется как T A ∈ 0 ; 1 и является количественной оценкой нечеткости, неопределенности, содержащейся в высказывании A .
Логическое отрицание нечеткого высказывания A обозначается ¬ A – это унарная (т.е. производимая над одним аргументом) логическая операция, результат которой является нечетким высказыванием «не A », «неверно, что A », значение истинности которого:
T ¬ A = 1 − T A .
Помимо приведенного выше исторически принятого основного определения нечеткого логического отрицания (нечеткого «НЕ»), введенного Заде, могут использоваться следующие альтернативные формулы:
T ¬ A = 1 − T A 1 + λT A , λ > − 1, – нечеткое λ -дополнение по Сугено;
T ¬ A = 1 − T A p , p > 0, – нечеткое p -дополнение по Ягеру.
Логическая конъюнкция нечетких высказываний A и B обозначается A ∩ B – это бинарная (т.е. производимая над двумя аргументами) логическая операция, результат которой является нечетким высказыванием « A и B », значение истинности которого:
T A ∩ B = min T A ; T B .
Помимо приведенного выше исторически принятого основного определения логической конъюнкции (нечеткого «И»), введенного Заде, могут использоваться следующие альтернативные формулы:
T A ∩ B = T A T B – в базисе Бандлера-Кохоута;
T A ∩ B = max T A + T B − 1 ; 0 – в базисе Лукашевича-Гилеса;
T A ∩ B = T B , при T A = 1 ; T A , при T B = 1 ; 0, в остальных случаях; – в базисе Вебера.
Логическая дизъюнкция нечетких высказываний A и B обозначается A ∪ B – это бинарная логическая операция, результат которой является нечетким высказыванием « A или B », значение истинности которого:
T A ∪ B = max T A ; T B .
Помимо приведенного выше исторически принятого основного определения логической дизъюнкции (нечеткого «ИЛИ»), введенного Заде, могут использоваться следующие альтернативные формулы:
T A ∪ B = T A + T B − T A T B – в базисе Бандлера-Кохоута;
T A ∪ B = min T A + T B ; 1 – в базисе Лукашевича-Гилеса;
T A ∪ B = T B , при T A = 0 ; T A , при T B = 0 ; 1, в остальных случаях; – в базисе Вебера.
Нечеткая импликация нечетких высказываний A и B обозначается A ⊃ B – это бинарная логическая операция, результат которой является нечетким высказыванием «из A следует B », «если A , то B », значение истинности которого:
T A ⊃ B = max min T A ; T B ; 1 − T A .
Помимо приведенного выше исторически принятого основного определения нечеткой импликации, введенного Заде, могут использоваться следующие альтернативные определения нечеткой импликации, предложенные различными исследователями в области теории нечетких множеств:
T A ⊃ B = max 1 − T A ; T B – Гедель;
T A ⊃ B = min T A ; T B – Мамдани;
T A ⊃ B = min 1 ; 1 − T A + T B – Лукашевич;
T A ⊃ B = min 1 ; T B T A , T A > 0 – Гоген;
T A ⊃ B = min T A + T B ; 1 – Лукашевич-Гилес;
T A ⊃ B = T A T B – Бандлер-Кохоут;
T A ⊃ B = max T A T B ; 1 − T A – Вади;
T A ⊃ B = 1, T A ≤ T B ; T B , T A > T B ; – Бауэр.
Общее число введенных определений нечеткой импликации не ограничивается приведенными выше. Большое количество работ по изучению различных вариантов нечеткой импликации обусловлено тем, что понятие нечеткой импликации является ключевым при нечетких выводах и принятии решений в нечетких условиях. Наибольшее применение при решении прикладных задач нечеткого управления находит нечеткая импликация Заде.
Нечеткая эквивалентность нечетких высказываний A и B обозначается A ≡ B – это бинарная логическая операция, результат которой является нечетким высказыванием « A эквивалентно B », значение истинности которого:
T A ≡ B = min max T ¬ A ; T B ;max T A ; T ¬ B .
Так же, как в классической бинарной логике, в нечеткой логике с помощью рассмотренных выше логических связок можно формировать достаточно сложные логические высказывания.
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.
Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.


Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).

Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.

Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.



