Технология intel hyper threading как включить. Где нужна Hyper-threading? Производительности всегда мало
В прошлом мы рассказывали о технологии одновременной многопоточности (Simultaneous Multi-Threading - SMT), которая применяется в процессорах Intel. И хотя первоначально она создавалась под кодовым именем "технология Джексона" (Jackson Technology) как возможный, вероятный вариант, Intel официально анонсировала свою технологию на форуме IDF прошлой осенью. Кодовое имя Jackson было заменено более подходящим Hyper-Threading. Итак, для того чтобы разобраться, как работает новая технология, нам нужны кое-какие первоначальные знания. А именно, нам нужно знать, что такое поток, как выполняются эти потоки. Почему работает приложение? Как процессор узнает, какие операции и над какими данными он должен совершать? Вся эта информация содержится в откомпилированном коде выполняемого приложения. И как только приложение получает от пользователя какую-либо команду, какие-либо данные, – процессору сразу же отправляются потоки, в результате чего он и выполняет то, что должен выполнить в ответ на запрос пользователя. С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда в вас попадает снаряд в Quake III Arena, или когда вы открываете документ Microsoft Word, процессору посылается определенный набор инструкций, которые он должен выполнить.
Процессор точно знает, где брать эти инструкции. Для этой цели предназначен редко упоминаемый регистр, называемый счетчиком команд (Program Counter, PC). Этот регистр указывает на место в памяти, где хранится следующая для выполнения команда. Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд, чтобы процессор знал, с какого именно места нужно начать выполнение. После каждой инструкции значение этого регистра увеличивается. Весь этот процесс выполняется до завершения потока. По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить. Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Но ограничение в этом процессе все равно существует – в каждую единицу времени можно выполнять лишь один поток.
Существует общеизвестный способ решения данной проблемы. Заключается он в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за ту же единицу времени могут выполнять уже два потока. Отметим, что этот способ не идеален. При нем возникает множество других проблем. С некоторыми, вы уже, вероятно, знакомы. Во-первых, несколько процессоров всегда дороже, чем один. Во-вторых, управлять двумя процессорами тоже не так-то просто. Кроме того, не стоит забывать о разделении ресурсов между процессорами. Например, до появления чипсета AMD 760MP, все x86 платформы с поддержкой многопроцессорности разделяли всю пропускную способность системной шины между всеми имеющимися процессорами. Но основной недостаток в другом – для такой работы и приложения, и сама операционная система должны поддерживать многопроцессорность. Способность распределить выполнение нескольких потоков по ресурсам компьютера часто называют многопоточностью. При этом и операционная система должна поддерживать многопоточность. Приложения также должны поддерживать многопоточность, чтобы максимально эффективно использовать ресурсы компьютера. Не забывайте об этом, когда мы будем рассматривать ещё один подход решения проблемы многопоточности, новую технологию Hyper-Threading от Intel.
Производительности всегда мало
Об эффективности всегда много говорят. И не только в корпоративном окружении, в каких-то серьезных проектах, но и в повседневной жизни. Говорят, homo sapiens лишь частично задействуют возможности своего мозга. То же самое относится и к процессорам современных компьютеров.
Взять, к примеру, Pentium 4. Процессор обладает, в общей сложности, семью исполнительными устройствами, два из которых могут работать с удвоенной скоростью – две операции (микрооперации) за такт. Но в любом случае, вы бы не нашли программы, которая смогла бы заполнить инструкциями все эти устройства. Обычные программы обходятся несложными целочисленными вычислениями, да несколькими операциями загрузки и хранения данных, а операции с плавающей точкой остаются в стороне. Другие же программы (например, Maya) главным образом загружают работой устройства для операций с плавающей точкой.
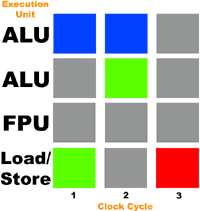
Чтобы проиллюстрировать ситуацию, давайте вообразим себе процессор с тремя исполнительными устройствами: арифметико-логическим (целочисленным – ALU), устройством для работы с плавающей точкой (FPU), и устройством загрузки/хранения (для записи и чтения данных из памяти). Кроме того, предположим, что наш процессор может выполнять любую операцию за один такт и может распределять операции по всем трем устройствам одновременно. Давайте представим, что к этому процессору на выполнение отправляется поток из следующих инструкций:
Рисунок ниже иллюстрирует уровень загруженности исполнительных устройств (серым цветом обозначается незадействованное устройство, синим – работающее устройство):
Итак, вы видите, что в каждый такт используется только 33% всех исполнительных устройств. В этот раз FPU остается вообще незадействованным. В соответствии с данными Intel, большинство программ для IA-32 x86 используют не более 35% исполнительных устройств процессора Pentium 4.
Представим себе ещё один поток, отправим его на выполнение процессору. На этот раз он будет состоять из операций загрузки данных, сложения и сохранения данных. Они будут выполняться в следующем порядке:

И снова загруженность исполнительных устройств составляет лишь на 33%.
Хорошим выходом из данной ситуации будет параллелизм на уровне инструкций (Instruction Level Parallelism - ILP). В этом случае одновременно выполняются сразу нескольких инструкций, поскольку процессор способен заполнять сразу несколько параллельных исполнительных устройств. К сожалению, большинство x86 программ не приспособлены к ILP в должной степени. Поэтому приходится изыскивать другие способы увеличения производительности. Так, например, если бы в системе использовалось сразу два процессора, то можно было бы одновременно выполнять сразу два потока. Такое решение называется параллелизмом на уровне потоков (thread-level parallelism, TLP). К слову сказать, такое решение достаточно дорогое.
Какие же ещё существуют способы увеличения исполнительной мощи современных процессоров архитектуры x86?
Hyper-Threading
Проблема неполного использования исполнительных устройств связана с несколькими причинами. Вообще говоря, если процессор не может получать данные с желаемой скоростью (это происходит в результате недостаточной пропускной способности системной шины и шины памяти), то исполнительные устройства будут использоваться не так эффективно. Кроме того, существует ещё одна причина – недостаток параллелизма на уровне инструкций в большинстве потоков выполняемых команд.
В настоящее время большинство производителей улучшают скорость работы процессоров путем увеличения тактовой частоты и размеров кэша. Конечно, таким способом можно увеличить производительность, но все же потенциал процессора не будет полностью задействован. Если бы мы могли одновременно выполнять несколько потоков, то мы смогли бы использовать процессор куда более эффективно. Именно в этом и заключается суть технологии Hyper-Threading.
Hyper-Threading – это название технологии, существовавшей и ранее вне x86 мира, технологии одновременной многопоточности (Simultaneous Multi-Threading, SMT). Идея этой технологии проста. Один физический процессор представляется операционной системе как два логических процессора, и операционная система не видит разницы между одним SMT процессором или двумя обычными процессорами. В обоих случаях операционная система направляет потоки как на двухпроцессорную систему. Далее все вопросы решаются на аппаратном уровне.
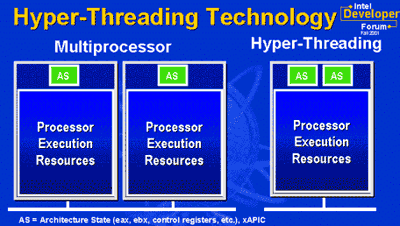
В процессоре с Hyper-Threading каждый логический процессор имеет свой собственный набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное выполнение инструкций выборки/декодирования в двух потоках. То есть такие инструкции выполняются поочередно. Параллельно же выполняются лишь обычные команды.
Официально технология была объявлена на форуме Intel Developer Forum прошлой осенью. Технология демонстрировалась на процессоре Xeon, где проводился рендеринг с помощью Maya. В этом тесте Xeon с Hyper-Threading показал на 30% лучшие результаты, чем стандартный Xeon. Приятный прирост производительности, но больше всего интересно то, что технология уже присутствует в ядрах Pentium 4 и Xeon, только она выключена.
Технология пока ещё не выпущена, однако те из вас, кто приобрел 0,13 мкм Xeon, и установил этот процессор на платы с обновленным BIOS, наверняка были удивлены, увидев в BIOS опцию включения/отключения Hyper-Threading.
А пока Intel будет оставлять опцию Hyper-Threading отключенной по умолчанию. Впрочем, для ее включения достаточно просто обновить BIOS. Все это касается рабочих станций и серверов, что же до рынка персональных компьютеров, в ближайшем будущем у компании планов касательно этой технологии не имеется. Хотя возможно, производители материнских плат предоставят возможность включить Hyper-Threading с помощью специального BIOS.
Остается очень интересный вопрос, почему Intel хочет оставить эту опцию выключенной?
Углубляемся в технологию
Помните те два потока из предыдущих примеров? Давайте на этот раз предположим, что наш процессор оснащен Hyper-Threading. Посмотрим, что получится, если мы попытаемся одновременно выполнить эти два потока:

Как и ранее, синие прямоугольники указывают на выполнение инструкции первого потока, а зеленые - на выполнение инструкции второго потока. Серые прямоугольники показывают незадействованные исполнительные устройства, а красные - конфликт, когда на одно устройство пришло сразу две разных инструкции из разных потоков.
Итак, что же мы видим? Параллелизм на уровне потоков дал сбой – исполнительные устройства стали использоваться ещё менее эффективно. Вместо параллельного выполнения потоков, процессор выполняет их медленнее, чем если бы он выполнял их без Hyper-Threading. Причина довольно проста. Мы пытались одновременно выполнить сразу два очень похожих потока. Ведь оба они состоят из операций по загрузке/сохранению и операций сложения. Если бы мы параллельно запускали "целочисленное" приложение и приложение, работающее с плавающей точкой, мы бы оказались куда в лучшей ситуации. Как видим, эффективность Hyper-Threading сильно зависит от вида нагрузки на ПК.
В настоящий момент, большинство пользователей ПК используют свой компьютер примерно так, как описано в нашем примере. Процессор выполняет множество очень схожих операций. К сожалению, когда дело доходит до однотипных операций, возникают дополнительные сложности с управлением. Случаются ситуации, когда исполнительных устройств нужного типа уже не осталось, а инструкций, как назло, вдвое больше обычного. В большинстве случаев, если бы процессоры домашних компьютеров использовали технологию Hyper-Threading, то производительность бы от этого не увеличилась, а может быть, даже снизилась на 0-10%.
На рабочих же станциях возможностей для увеличения производительности у Hyper-Threading больше. Но с другой стороны, все зависит от конкретного использования компьютера. Рабочая станция может означать как high-end компьютер для обработки 3D графики, так и просто сильно нагруженный компьютер.
Наибольший же прирост в производительности от использования Hyper-Threading наблюдается в серверных приложениях. Главным образом это объясняется широким разнообразием посылаемых процессору операций. Сервер баз данных, использующих транзакции, может работать на 20-30% быстрее при включенной опции Hyper-Threading. Чуть меньший прирост производительности наблюдается на веб-серверах и в других сферах.
Максимум эффективности от Hyper-Threading
Вы думаете, Intel разработала Hyper-Threading только лишь для своей линейки серверных процессоров? Конечно же, нет. Если бы это было так, они бы не стали впустую тратить место на кристалле других своих процессоров. По сути, архитектура NetBurst, использующаяся в Pentium 4 и Xeon, как нельзя лучше подходит для ядра с поддержкой одновременной многопоточности. Давайте ещё раз представим себе процессор. На этот раз в нем будет ещё одно исполнительное устройство – второе целочисленное устройство. Посмотрим, что случится, если потоки будут выполняться обоими устройствами:
С использованием второго целочисленного устройства, единственный конфликт случился только на последней операции. Наш теоретический процессор в чем-то похож на Pentium 4. В нем имеется целых три целочисленных устройства (два ALU и одно медленное целочисленное устройство для циклических сдвигов). А что ещё более важно, оба целочисленных устройства Pentium 4 способны работать с двойной скоростью – выполнять по две микрооперации за такт. А это, в свою очередь, означает, что любое из этих двух целочисленных устройств Pentium 4/Xeon могло выполнить те две операции сложения из разных потоков за один такт.
Но это не решает нашей проблемы. Было бы мало смысла просто добавлять в процессор дополнительные исполнительные устройства с целью увеличения производительности от использования Hyper-Threading. С точки зрения занимаемого на кремнии пространства это было бы крайне дорого. Вместо этого, Intel предложила разработчикам оптимизировать программы под Hyper-Threading.
Используя инструкцию HALT, можно приостановить работу одного из логических процессоров, и тем самым увеличить производительность приложений, которые не выигрывают от Hyper-Threading. Итак, приложение не станет работать медленнее, вместо этого один из логических процессоров будет остановлен, и система будет работать на одном логическом процессоре – производительность будет такой же, что и на однопроцессорных компьютерах. Затем, когда приложение сочтет, что от Hyper-Threading оно выиграет в производительности, второй логический процессор просто возобновит свою работу.
На веб-сайте Intel имеется презентация , описывающая, как именно необходимо программировать, чтобы извлечь из Hyper-Threading максимум выгоды.
Выводы
Хотя мы все были крайне обрадованы, когда до нас дошли слухи об использовании Hyper-Threading в ядрах всех современных Pentium 4/Xeon, все же это не будет бесплатной производительностью на все случаи жизни. Причины ясны, и технологии предстоит преодолеть ещё многое, прежде чем мы увидим Hyper-Threading, работающую на всех платформах, включая домашние компьютеры. А при поддержке разработчиков, технология определенно может оказаться хорошим союзником Pentium 4, Xeon, и процессорам будущего поколения от Intel.
При существующих ограничениях и при имеющейся технологии упаковки, Hyper-Threading кажется более разумным выбором для потребительского рынка, чем, например, подход AMD в SledgeHammer – в этих процессорах используется целых два ядра. И до тех пор, пока не станут совершенными технологии упаковки, такие как Bumpless Build-Up Layer , стоимость разработки многоядерных процессоров может оказаться слишком высокой.
Интересно заметить, насколько разными стали AMD и Intel за последние несколько лет. Ведь когда-то AMD практически копировала процессоры Intel. Теперь же компании выработали принципиально иные подходы к будущим процессорам для серверов и рабочих станций. AMD на самом деле проделала очень длинный путь. И если в процессорах Sledge Hammer действительно будут использоваться два ядра, то по производительности такое решение будет эффективнее, чем Hyper-Threading. Ведь в этом случае кроме удвоения количества всех исполнительных устройств снимаются проблемы, которые мы описали выше.
Hyper-Threading ещё некоторое время не появится на рынке обычных ПК, но при хорошей поддержке разработчиков, она может стать очередной технологией, которая опустится с серверного уровня до простых компьютеров.
20 января 2015 в 19:43Еще раз о Hyper-Threading
- Тестирование IT-систем ,
- Программирование
Было время, когда понадобилось оценить производительность памяти в контексте технологии Hyper-threading . Мы пришли к выводу, что ее влияние не всегда позитивно. Когда появился квант свободного времени, возникло желание продолжить исследования и рассмотреть происходящие процессы с точностью до машинных тактов и битов, используя программное обеспечение собственной разработки.
Исследуемая платформа
Объект экспериментов – ноутбук ASUS N750JK c процессором Intel Core i7-4700HQ. Тактовая частота 2.4GHz, повышаемая в режиме Intel Turbo Boost до 3.4GHz. Установлено 16 гигабайт оперативной памяти DDR3-1600 (PC3-12800), работающей в двухканальном режиме. Операционная система – Microsoft Windows 8.1 64 бита.Рис.1 Конфигурация исследуемой платформы.
Процессор исследуемой платформы содержит 4 ядра, что при включении технологии Hyper-Threading обеспечивает аппаратную поддержку 8 потоков или логических процессоров. Эту информацию Firmware платформы передает операционной системе посредством ACPI-таблицы MADT (Multiple APIC Description Table). Поскольку платформа содержит только один контроллер оперативной памяти, таблица SRAT (System Resource Affinity Table), декларирующая приближенность процессорных ядер к контроллерам памяти, отсутствует. Очевидно, исследуемый ноутбук не является NUMA-платформой , но операционная система, в целях унификации, рассматривает его как NUMA-систему с одним доменом, о чем говорит строка NUMA Nodes = 1. Факт, принципиальный для наших экспериментов – кэш память данных первого уровня имеет размер 32 килобайта на каждое из четырех ядер. Два логических процессора, разделяющие одно ядро, используют кэш-память первого и второго уровней совместно.
Исследуемая операция
Исследовать будем зависимость скорости чтения блока данных от его размера. Для этого выберем наиболее производительный метод, а именно чтение 256-битных операндов посредством AVX-инструкции VMOVAPD. На графиках по оси X отложен размер блока, по оси Y – скорость чтения. В окрестности точки X, соответствующей размеру кэш-памяти первого уровня, ожидаем увидеть точку перегиба, поскольку производительность должна упасть после того, как обрабатываемый блок выйдет за пределы кэш-памяти. В нашем тесте, в случае многопоточной обработки, каждый из 16 инициируемых потоков, работает с отдельным диапазоном адресов. Для управления технологией Hyper-Threading в рамках приложения, в каждом из потоков используется API-функция SetThreadAffinityMask, задающая маску, в которой каждому логическому процессору соответствует один бит. Единичное значение бита разрешает использовать заданный процессор заданным потоком, нулевое значение – запрещает. Для 8 логических процессоров исследуемой платформы, маска 11111111b разрешает использовать все процессоры (Hyper-Threading включен), маска 01010101b разрешает использовать по одному логическому процессору в каждом ядре (Hyper-Threading выключен).На графиках используются следующие сокращения:
MBPS (Megabytes per Second) – скорость чтения блока в мегабайтах в секунду ;
CPI (Clocks per Instruction) – количество тактов на инструкцию ;
TSC (Time Stamp Counter) – счетчик процессорных тактов .
Примечание.Тактовая частота регистра TSC может не соответствовать тактовой частоте процессора при работе в режиме Turbo Boost. Это необходимо учитывать при интерпретации результатов.
В правой части графиков визуализируется шестнадцатеричный дамп инструкций, составляющих тело цикла целевой операции, выполняемой в каждом из программных потоков, или первые 128 байт этого кода.
Опыт №1. Один поток

Рис.2 Чтение одним потоком
Максимальная скорость 213563 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт.
Опыт №2. 16 потоков на 4 процессора, Hyper-Threading выключен

Рис.3 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно четырем
Hyper-Threading выключен. Максимальная скорость 797598 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт. Как и ожидалось, по сравнению с чтением одним потоком, скорость выросла приблизительно в 4 раза, по количеству работающих ядер.
Опыт №3. 16 потоков на 8 процессоров, Hyper-Threading включен

Рис.4 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно восьми
Hyper-Threading включен. Максимальная скорость 800722 мегабайт в секунду, в результате включения Hyper-Threading почти не выросла. Большой минус – точка перегиба имеет место при размере блока около 16 килобайт. Включение Hyper-Threading немного увеличило максимальную скорость, но падение скорости теперь наступает при вдвое меньшем размере блока – около 16 килобайт, поэтому существенно упала средняя скорость. Это не удивительно, каждое ядро имеет собственную кэш-память первого уровня, в то время, как логические процессоры одного ядра, используют ее совместно.
Выводы
Исследованная операция достаточно хорошо масштабируется на многоядерном процессоре. Причины – каждое из ядер содержит собственную кэш-память первого и второго уровней, размер целевого блока сопоставим с размером кэш-памяти, и каждый из потоков работает со своим диапазоном адресов. В академических целях мы создали такие условия в синтетическом тесте, понимая, что реальные приложения обычно далеки от идеальной оптимизации. А вот включение Hyper-Threading, даже в этих условиях дало негативный эффект, при небольшой прибавке пиковой скорости, имеет место существенный проигрыш в скорости обработки блоков, размер которых находится в диапазоне от 16 до 32 килобайт.Под названием Hyper-Threading.
Терминология
Терминология в мире технологий может быть запутанной и легко
забывается, поэтому давайте начнем с разъяснения значения терминов,
которые я буду использовать здесь. Многоядерным процессором называется
процессор, содержащий более одного ядра в одной интегральной схеме.
Многочиповый означает несколько микросхем, объединенных вместе.
Многопроцессорный означает несколько отдельных процессоров, совместно
работающих в одной системе. И конечно, ЦП означает центральный
процессор, имеющий одно или более ядер, каждое из которых имеет
устройство выполнения (с которого и выполняется вся математика).
Hyper-Threading
Так что же такое технология hyper-threading? Термин Hyper-threading
используется компанией Intel для определения их технологии, которая
позволяет операционной системе воспринимать одно ядро ЦП, как два ядра.
Таким образом, операционная система работает с таким ядром так же, как с
любым многоядерным чипом, направляя на него одновременно несколько
процессов. Хотя при помощи этой технологии можно заставить систему
воспринимать одно ядро, как три или более ядер, сложность архитектуры
ограничила компанию Intel до выпуска hyper-threaded ядер, которые могут
восприниматься только как два ядра.
Здесь нет никакого фокуса. Компания Intel разработала архитектуру
чипа для обработки процессов так же, как это делают многоядерные
процессоры. По сути, компания Intel дублировала интенсивно используемые
области ядра ЦП и обеспечила использование этих секций несколькими
процессами одновременно. Поскольку эти области ядра являются раздельными
(они находятся на одном кристалле, но используют различные области
этого кристалла), эти процессы не мешают друг другу. Такие
hyper-threading-совместимые ядра представляют собой не совсем то же
самое, что многоядерные процессоры; не любой процесс может одновременно
выполняться с другим процессом, он должен использовать отдельную часть
ядра для своих операций.
Hyper-threading представляет собой пример одновременной
многопоточности (Simultaneous Multi-Threading - SMT). SMT является одним
из двух типов многопоточности. Другой тип называется временной
многопоточностью (Temporal Multi-Threading - TMT). При TMT ядро
процессора выполняет инструкции сначала от одного потока, затем от
другого, и затем снова от первого, и поэтому пользователю кажется, что
выполняется сразу два потока, когда на самом деле потоки просто делят
время ЦП между собой. При SMT инструкции от каждого потока могут
выполняться одновременно. Эти технологии могут использоваться для
повышения производительности.
Пользователям также следует знать, что не все ОС поддерживают
технологию hyper-threading. По заявлению компании Intel следующие ОС от
Microsoft полностью оптимизированы под поддержку технологии
hyper-threading:
Microsoft Windows XP Professional Edition
Microsoft Windows XP Home Edition
Microsoft Windows Vista Home Basic
Microsoft Windows Vista Home Premium
Microsoft Windows Vista Home Ultimate
Microsoft Windows Vista Home Business
И как говорят в компании Intel, следующие ОС не полностью
оптимизированы под технологию hyper-threading, и поэтому данная
технология должна быть отключена в настройках BIOS:
Microsoft Windows 2000 (все версии)
Microsoft Windows NT 4.0
Microsoft Windows ME
Microsoft Windows 98
Microsoft Windows 98 SE
Иногда у таких приложений, как FireFox ,
возникают проблемы с hyper-threading. Лучшим способом решения этой
проблемы является запуск приложения в режиме совместимости с Windows 98.
Для этого нужно нажать правой клавишей мыши на значке приложения,
перейти в свойства, выбрать совместимость и отметить флажком опцию
"Запустить приложение в режиме совместимости (Run this program in
compatibility mode)", выбрав Windows 98. Это отключит технологию
hyper-threading для данного приложения, поскольку Windows 98 не
поддерживает hyper-threading.
Преимущества Hyper-Threading
Есть множество преимуществ hyper-threading. Компания Intel
утверждает, что дублирование определенных областей ядра ЦП увеличивает
размер ядра примерно на 5 процентов, но при этом обеспечивает прирост
производительности на 30 процентов по сравнению с другими идентичными
ядрами процессоров без hyper-threading.
Недостатки Hyper-Threading
advertisement
//
//]]-->

Хотя hyper-threaded ядра ЦП не обеспечивают полного объема
преимуществ многоядерных процессоров, они все же имеют значительные
преимущества по сравнению с обычными одноядерными процессорами. Конечно,
всегда полезно знать о том, какие недостатки имеются у технологии,
прежде чем ее использовать. Одним недостатком многих применений является
высокий уровень энергопотребления. Поскольку все области ядра нуждаются
в питании (даже в режиме ожидания), общий уровень энергопотребления
hyper-threading ядер, а также всех ядер с поддержкой SMT, выше. Без
максимального использования улучшений скорости, предлагаемых
hyper-threaded ядром, оно просто будет ядром, потребляющим больше
электроэнергии. Для многих ситуаций, включая фермы серверов, и мобильные
компьютеры, такое повышенное энергопотребление нежелательно.
Более того, если сравнить hyper-threaded ядро ЦП с non-hyper-threaded
ядром, вы заметите значительное повышение переполнения кэша. ARM
утверждает, что это повышение может составлять до 42%. Сравните это
значение с многоядерными процессорами, где переполнение кэша снижено на
37%, и это действительно станет важным.
Теперь, после прочтения информации обо всех этих недостатках вы,
возможно, решите, что эти hyper-threaded ядра бесполезны. И вы правы, в
некоторых ситуациях. Например, если энергопотребление является основным
аспектом в вашей ситуации, то hyper-threaded ядра (или любые другие ядра
с поддержкой SMT) будут нежелательными. Однако даже если потребление
мощности стоит высоко в списке ваших требований, hyper-threaded ядра
могут быть подходящим вариантом. Возьмём для примера серверную ферму.
Обычно во внимание принимается энергопотребление фермами серверов (эти
счета могут составлять многие тысячи долларов в месяц!). Однако в
сегодняшних фермах серверов многие серверы являются виртуальными.
Поэтому вполне может быть, что у вас есть несколько виртуальных серверов
на одном физическом сервере, при этом требования производительности
этих серверов не выше среднего. Вполне возможно, что такой тип
конфигурации обеспечит достаточный уровень использования ЦП, чтобы
использовать максимальный объем производительности hyper-threaded ядер,
при этом энергопотребление будет сведено до минимума.
Как всегда, важно четко учитывать все рабочие обстоятельства, прежде
чем решить использовать технологию. Технологий без недостатков
практически не бывает. Как правило, польза или бесполезность
определенной технологии применительно к вашей ситуации выявляется только
после тщательного пересмотра всех ее достоинств и недостатков.
Hyper-threading - это всего лишь технология. Для дополнительной
информации по этой теме рекомендую прочесть две мои предыдущие статьи. Во-первых, статью о , в которой объясняется, как многоядерные процессоры получают доступ к кэш-памяти. Во-вторых, мою статью о сродстве процессоров ,
в которой говорится о взаимодействии между приложениями и
множественными ядрами. Если у вас возникли вопросы о моей статье,
присылайте их мне на почту, и я постараюсь ответить как можно быстрее.
Рассел
Хичкок (Russell Hitchcock) работает консультантом, в его обязанности
входит сетевое аппаратное обеспечение (networked hardware), контрольные
системы и антенны. Рассел также пишет технические статьи на различные
Впервые технология Hyper-Threading (HT, гиперпоточность) появилась 15 лет назад - в 2002 году, в процессорах Pentium 4 и Xeon, и с тех пор то появлялась в процессорах Intel (в линейке Core i, некоторых Atom, в последнее время еще и в Pentium), то исчезала (ее поддержки не было в линейках Core 2 Duo и Quad). И за это время она обросла мифическими свойствами - дескать ее наличие чуть ли не удваивает производительность процессора, превращая слабые i3 в мощные i5. При этом другие говорят что HT - обычная маркетинговая уловка, и толку от нее мало. Правда как обычно по середине - местами толк от нее есть, но двухкртаного прироста ждать точно не стоит.
Техническое описание технологии
Начнем с определения, данного на сайте Intel:
Технология Intel® Hyper-Threading (Intel® HT) обеспечивает более эффективное использование ресурсов процессора, позволяя выполнять несколько потоков на каждом ядре. В отношении производительности эта технология повышает пропускную способность процессоров, улучшая общее быстродействие многопоточных приложений.
В общем понятно то, что ничего не понятно - одни общие фразы, однако вкраце технологию они описывают - HT позволяет одному физическому ядру обрабатывать одновременно несколько (обычно два) логических потока. Но как? Процессор, поддерживающий гиперпоточность:
- может хранить информацию сразу о нескольких выполняющихся потоках;
- содержит по одному набору регистров (то есть блоков быстрой памяти внутри процессора) и по одному контроллеру прерываний (то есть встроенному блоку процессора, отвечающему за возможность последовательной обработки запросов о наступлении какого-либо события, требующего немедленного внимания, от разных устройств) на каждый логический процессор.

Допустим перед процессором стоят две задачи. Если процессор имеет одно ядро, то он будет выполнять их последовательно, если два - то параллельно на двух ядрах, и время выполнения обеих задач будет равно времени, затраченному на более тяжелую задачу. Но что если процессор одноядерный, но поддерживает гиперпоточность? Как видно на картинке выше при выполнении одной задачи процессор не занят на 100% - какие-то блоки процессора банально не нужны в данной задаче, где-то ошибается модуль предсказания переходов (который нужен для предсказания, будет ли выполнен условный переход в программе), где-то происходит ошибка обращения к кэшу - в общем и целом при выполнении задачи процессор редко бывает занят больше, чем на 70%. А технология HT как раз «подпихивает» незанятым блокам процессора вторую задачу, и получается что одновременно на одном ядре обрабатываются две задачи. Однако удвоения производительности не происходит по понятным причинам - очень часто получается так, что двум задачам нужен один и тот же вычислительный блок в процессоре, и тогда мы видим простой: пока одна задача обрабатывается, выполнение второй на это время просто останавливается (синие квадраты - первая задача, зеленые - вторая, красные - обращение задач к одному и тому же блоку в процессоре):

В итоге время, затраченное процессором с HT на две задачи, оказывается больше времени, требуемого на вычисление самой тяжелой задачи, но меньше того времени, которое нужно для последовательного вычисления обеих задач.
Плюсы и минусы технологии
С учетом того, что кристалл процессора с поддержкой HT физчески больше кристалла процессора без HT в среднем на 5% (именно столько занимают дополнительные блоки регистров и контроллеры прерываний), а поддержка HT позволяет нагрузить процессор на 90-95%, то в сравнении с 70% без HT мы получаем, что прирост в лучшем случае будет 20-30% - цифра достаточно большая.
Однако не все так хорошо: бывает, что прироста производительности от HT нет вообще, и даже бывает так, что HT ухудшает производительность процессора. Это бывает по многим причинам:
- Нехватка кэш-памяти. К примеру в современных четырехядерных i5 находится 6 мб кэша L3 - по 1.5 мб на ядро. В четырехядерных i7 с HT кэша уже 8 мб, но так как логических ядер 8, то мы получаем уже только 1 мб на ядро - при вычислениях некоторым программам этого объема может не хватать, что приводит к падению производительности.
- Отсутствие оптимизации ПО. Самая основная проблема - программы считают логические ядра физическими, из-за чего при параллельном выполнении задач на одном ядре часто возникают задержки из-за обращения задач к одному и тому же вычислительному блоку, что в итоге сводит сводит прирост производительности от HT на нет.
- Зависимость данных. Вытекает из предыдущего пункта - для выполнения одной задачи требуется результат другой, а она еще не выполнена. И опять же мы получаем простой, снижение загрузки на процессор и небольшой прирост от HT.
Таких много, ибо для вычислений HT это манна небесная - тепловыделение практически не растет, процессор особо больше не становится, а при правильной оптимизации можно получить прирост до 30%. Поэтому ее поддержку быстро внедрили в те программы, где легко можно сделать распараллеливание нагрузки - в архиваторы (WinRar), программы для 2D/3D моделирования (3ds Max, Maya), программы для обрабокти фото и видео (Sony Vegas, Photoshop, Corel Draw).
Программы, плохо работающие с гиперпоточностью
Традиционно это большинство игр - их обычно бывает трудно грамотно распараллелить, поэтому зачастую четырех физических ядер на высоких частотах (i5 K-серии) более чем хватает для игр, распараллелить которые под 8 логических ядер в i7 оказывается непосильной задачей. Однако стоит учитывать и то, что есть фоновые процессы, и если процессор не поддерживает HT, то их обработка ложится на физические ядра, что может замедлить игру. Тут i7 с HT оказывается в выигрыше - все фоновые задачи традиционно имеют пониженный приоритет, поэтому при одновременной работе на одном физическом ядре игры и фоновой задаче игра будет получать повышенный приоритет, и при этом фоновая задача не будет «отвлекать» занятые игрой ядра - именно поэтому для стриминга или записи игр лучше брать i7 с гиперпоточностью.
Итоги
Пожалуй тут остается только один вопрос - так имеет ли смысл брать процессоры с HT или нет? Если вы любите держать одновременно открытыми пяток программ и при этом играть в игры, или же занимаетесь обработкой фото, видео или моделированием - да, разумеется стоит брать. А если вы привыкли перед запуском тяжелой программы закрывать все другие, и не балуетесь обработкой или моделированием, то процессор с HT вам ни к чему.
Было время, когда понадобилось оценить производительность памяти в контексте технологии Hyper-threading . Мы пришли к выводу, что ее влияние не всегда позитивно. Когда появился квант свободного времени, возникло желание продолжить исследования и рассмотреть происходящие процессы с точностью до машинных тактов и битов, используя программное обеспечение собственной разработки.
Исследуемая платформа
Объект экспериментов – ноутбук ASUS N750JK c процессором Intel Core i7-4700HQ. Тактовая частота 2.4GHz, повышаемая в режиме Intel Turbo Boost до 3.4GHz. Установлено 16 гигабайт оперативной памяти DDR3-1600 (PC3-12800), работающей в двухканальном режиме. Операционная система – Microsoft Windows 8.1 64 бита.Рис.1 Конфигурация исследуемой платформы.
Процессор исследуемой платформы содержит 4 ядра, что при включении технологии Hyper-Threading обеспечивает аппаратную поддержку 8 потоков или логических процессоров. Эту информацию Firmware платформы передает операционной системе посредством ACPI-таблицы MADT (Multiple APIC Description Table). Поскольку платформа содержит только один контроллер оперативной памяти, таблица SRAT (System Resource Affinity Table), декларирующая приближенность процессорных ядер к контроллерам памяти, отсутствует. Очевидно, исследуемый ноутбук не является NUMA-платформой , но операционная система, в целях унификации, рассматривает его как NUMA-систему с одним доменом, о чем говорит строка NUMA Nodes = 1. Факт, принципиальный для наших экспериментов – кэш память данных первого уровня имеет размер 32 килобайта на каждое из четырех ядер. Два логических процессора, разделяющие одно ядро, используют кэш-память первого и второго уровней совместно.
Исследуемая операция
Исследовать будем зависимость скорости чтения блока данных от его размера. Для этого выберем наиболее производительный метод, а именно чтение 256-битных операндов посредством AVX-инструкции VMOVAPD. На графиках по оси X отложен размер блока, по оси Y – скорость чтения. В окрестности точки X, соответствующей размеру кэш-памяти первого уровня, ожидаем увидеть точку перегиба, поскольку производительность должна упасть после того, как обрабатываемый блок выйдет за пределы кэш-памяти. В нашем тесте, в случае многопоточной обработки, каждый из 16 инициируемых потоков, работает с отдельным диапазоном адресов. Для управления технологией Hyper-Threading в рамках приложения, в каждом из потоков используется API-функция SetThreadAffinityMask, задающая маску, в которой каждому логическому процессору соответствует один бит. Единичное значение бита разрешает использовать заданный процессор заданным потоком, нулевое значение – запрещает. Для 8 логических процессоров исследуемой платформы, маска 11111111b разрешает использовать все процессоры (Hyper-Threading включен), маска 01010101b разрешает использовать по одному логическому процессору в каждом ядре (Hyper-Threading выключен).На графиках используются следующие сокращения:
MBPS (Megabytes per Second) – скорость чтения блока в мегабайтах в секунду ;
CPI (Clocks per Instruction) – количество тактов на инструкцию ;
TSC (Time Stamp Counter) – счетчик процессорных тактов .
Примечание.Тактовая частота регистра TSC может не соответствовать тактовой частоте процессора при работе в режиме Turbo Boost. Это необходимо учитывать при интерпретации результатов.
В правой части графиков визуализируется шестнадцатеричный дамп инструкций, составляющих тело цикла целевой операции, выполняемой в каждом из программных потоков, или первые 128 байт этого кода.
Опыт №1. Один поток
Рис.2 Чтение одним потоком
Максимальная скорость 213563 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт.
Опыт №2. 16 потоков на 4 процессора, Hyper-Threading выключен
Рис.3 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно четырем
Hyper-Threading выключен. Максимальная скорость 797598 мегабайт в секунду. Точка перегиба имеет место при размере блока около 32 килобайт. Как и ожидалось, по сравнению с чтением одним потоком, скорость выросла приблизительно в 4 раза, по количеству работающих ядер.
Опыт №3. 16 потоков на 8 процессоров, Hyper-Threading включен
Рис.4 Чтение шестнадцатью потоками. Количество используемых логических процессоров равно восьми
Hyper-Threading включен. Максимальная скорость 800722 мегабайт в секунду, в результате включения Hyper-Threading почти не выросла. Большой минус – точка перегиба имеет место при размере блока около 16 килобайт. Включение Hyper-Threading немного увеличило максимальную скорость, но падение скорости теперь наступает при вдвое меньшем размере блока – около 16 килобайт, поэтому существенно упала средняя скорость. Это не удивительно, каждое ядро имеет собственную кэш-память первого уровня, в то время, как логические процессоры одного ядра, используют ее совместно.



